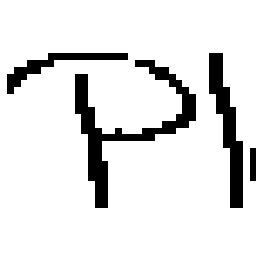
Kapitel 3 - Systemkomponenten
Dieses Kapitel beschreibt das im vorangehenden Kapitel vorgestellte System detaillierter. Hierbei wird hauptsächlich auf die verwendeten Algorithmen und Methoden der Bildverarbeitung und Mustererkennung eingegangen. Die vermittelten Ideen und Lösungen werden losgelöst von der gewählten Implementation vorgestellt und sollen unabhängig von dieser verwendet und verstanden werden können. Das objektorientierte Design des Systems und die konkrete Implementation der einzelnen Komponenten wird erst im Kapitel 4 beschrieben.
3.1 Systemaufbau und Datenfluss
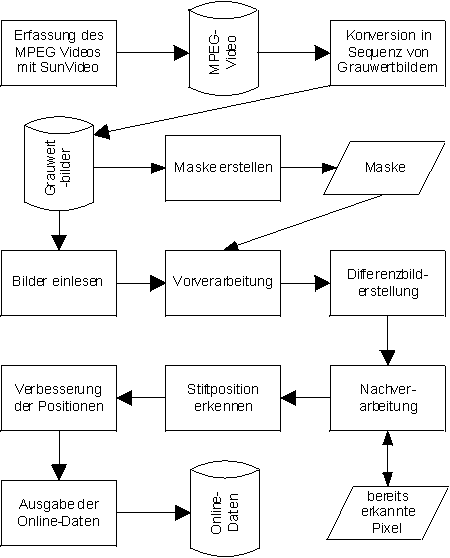
Dieser Abschnitt vermittelt einen groben Überblick. Die genaue Funktionsweise der einzelnen Komponenten kann den nachfolgenden Erläuterungen dieses Kapitels entnommen werden. Bild 13 und die zusammenfassenden Erläuterungen von Kapitel 2 können helfen, den Überblick über den Zusammenhang der Komponenten zu wahren.
Der Datenfluss von Bild 13 entspricht weitgehend dem vereinfachten Datenfluss aus dem Kapitel 2. Zuerst werden die Videobilder mit spezieller Hardware erfasst, als MPEG-Datei abgespeichert und indirekt über eine Sequenz von TrueColor-Bildern in eine Sequenz von Graustufenbildern konvertiert.
Wie in Kapitel 2 bereits beschrieben, werden die Bilder der Bildsequenz am Anfang der Verarbeitung eingelesen und vorverarbeitet. Zwischen jeweils zwei aufeinanderfolgenden vorbereiteten Bildern wird das Differenzbild berechnet. Zur Verbesserung der Qualität werden Störungen durch Teile des Stifts oder der Hand mit Hilfe einer Anzahl unmittelbar nachfolgender Bilder korrigiert. In der Nachverarbeitung werden alle bereits erkannten Bildpunkte des Schriftzuges eliminiert. So kann sicher gegangen werden, dass kein Teil des Schriftzuges mehrfach erkannt wird.
Das resultierende Differenzbild wird danach aufgrund seines Histogramms in ein binäres Bild umgewandelt. Jeder schwarze Bildpunkt wird in eine Punktmenge aufgenommen. Das Zentrum resp. der Mittelpunkt dieser Punktmenge ist die aktuelle Position des Stifts. Sind diese schwarzen Punkte zu grossflächig über den Bildausschnitt verteilt oder gibt es gar keine schwarzen Punkte, dann hat der Stift keine Position, d.h. er war in der Luft (Pen-Up) und gar nicht auf dem Papier abgesetzt (Pen-Down).
Die Qualität dieser Punktfolge wird schliesslich durch lineare Interpolation weiter verbessert. Hierbei werden kurze Unterbrüche in den Stiftpositionen ergänzt und zu lange Striche im Linienzug eliminiert. Diese verbesserte Punktfolge wird schliesslich in einem speziellen Online-Format gespeichert.
Bild 13: Datenfluss durch die Systemkomponenten
3.2 Einlesen und Vorverarbeiten der Bilder
3.2.1 Konvertierung des MPEG-Videos in Einzelbilder
Das Videosignal wird auf der SUN-Workstation mit SunVideo (1) in einer MPEG-Datei gespeichert. Diese Datei wird in eine Sequenz von PPM-Bildern (2) konvertiert. Hierzu wird das Programm mpeg2decode (3) verwendet. Der belegte Speicherplatz dieser Einzelbilder ist ca. siebenmal grösser als die vorangehende MPEG-Datei. Um Speicherplatz und Verarbeitungszeit zu gewinnen, wurde die Konvertierung der TrueColor-Bilder in Graustufenbilder bereits an den Einzelbildern auf der Festplatte vorgenommen. Dies wird vom Programm ppmtopgm (4) erledigt. Hierdurch belegen die Einzelbilder nur noch ca. 2.5 mal soviel Speicherplatz wie die MPEG-Datei. Im Durchschnitt belegt die MPEG-Datei einer Textzeile (1.5 cm hoch, 12 cm lang, 3 bis 6 Worte) 30 MB und die zugehörigen Einzelbilder 75 MB Speicherplatz.
3.2.2 Beschränkung der Einzelbilder
Vor der Verarbeitung der Bilder legt der Benutzer manuell fest, welches Intervall der Bildsequenz betrachtet werden soll. Dies ist notwendig, da oft viele überzählige Bilder vor und nach dem Schreiben der Textzeile erfasst werden. Auch kann es nötig sein, nur ein einzelnes Wort aus der Textzeile zu verarbeiten. Es wäre unsinnig alle Bilder zu verarbeiten, wenn das entsprechende Wort nur in einem Teilintervall der Bildsequenz entstanden ist. Ausserdem wird die Verarbeitung auf einen Bereich um die Textzeile bzw. um das Wort beschränkt. Dieser Bereich ist ein achsenparalleles Rechteck, welches den gewünschten Bereich möglichst eng umschliesst (Bounding-Box). Dieser Bereich sollte nicht zu eng gewählt werden, da es nicht auszuschliessen ist, dass sich die Position des geschriebenen Texts aufgrund von Verschiebungen des Papiers durch den Schreiber verändert. Durch die Beschränkung auf ein Zeitintervall und eine Bounding-Box wird die Verarbeitung auf das Wesentliche reduziert. Hierdurch wird die Geschwindigkeit gesteigert und mögliche Störquellen vermindert.
3.2.3 Generierung der Maske
Um die Suche nach Stiftpositionen noch weiter zu beschränken wird der betrachtete Bildausschnitt der Bounding-Box mit einer enganliegenden Maske um die Schriftlinien noch weiter verengt. Diese Maske beschränkt sich auf die Umgebung des geschrieben Texts und extrahiert aus dem Bild der Sequenz einen kleinen repräsentativen Teil.
Zur Generierung der Maske wird das letzte Bild des Intervalls eingelesen und in einem zweidimensionalen Byte-Feld abgespeichert. Hierdurch werden die 256 Graustufen der einzelnen Bildpunkte repräsentiert. Das Bild wird nun um 180° rotiert und auf den Ausschnitt der Bounding-Box beschnitten. Der Algorithmus von N. Otsu [Ots79] berechnet aus dem Histogramm (Häufigkeit der einzelnen Grauwerte) des Bildausschnittes einen sinnvollen Schwellwert (engl. Threshold) für eine Binärisierung. Die Funktionsweise des Algorithmus von Otsu wird weiter hinten im Abschnitt "3.6 Stiftpositionen erfassen" genauer erläutert. Diese Binärisierung wird mit dem errechneten Schwellwert auf dem Bild ausgeführt und extrahiert den Schriftzug aus dem Grauwert-Bild (vgl. Bild 14).
| Originalausschnitt |
|
| Binärisierung |
|
| Expansion in 3 Schritten |
|
Bild 14: Generierung der Maske – vom Originalausschnitt (oben) über die Binärisierung (mitte) zu einer expandierten Maske (unten)
Der binärisierte Schriftzug wird dann expandiert und in einem eigenen zweidimensionalen binären Feld abgespeichert. Hierbei wird in mehreren Iterationen jedes Pixel schwarz eingefärbt welches ein schwarzes Pixel in seiner 8-Nachbarschaft (5) hat. Zwei bis drei Expansionsschritte haben sich als sinnvoll erwiesen. Bild 15 zeigt einen Vergleich der verschiedenen Expansionsstufen.
|
|
|
|
Bild 15: Vergleich verschiedener Expansionsstufen der Maske. Das Spektrum reicht von einfacher Expansion (oben links) bis zu vierfacher Expansion (unten rechts)
Die Maske darf den Schriftzug nicht zu eng umschliessen. Das Blatt Papier ist zwar auf dem Pult fixiert, doch es ist trotzdem beweglich. Hierbei ändert der Schriftzug seine Position. Wenn die Maske den Schriftzug zu eng umschliessen würde, könnte es vorkommen, dass wie in Bild 16 Teile davon ausserhalb der Maske liegen würden.
|
|
|
Bild 16: Positionen des Schriftzuges innerhalb seiner Maske zu verschiedenen Zeitpunkten. Die zu beobachtende starke Bewegung wurde durch die Verschiebung des Papiers während des Schreibens ausgelöst.
Ausserdem besteht der Schriftzug im Videofilm nicht aus einem scharfen, schwarzen Linienzug, sondern aus einem Band von Grauwerten. Diese Grauwerte sind im Innern des Linienzuges sehr dunkel und gehen wie beim Wort "wall" in Bild 17 gegen den Rand des Schriftzuges in die Helligkeit des Hintergrundes über. Unschwer sind in Bild 17 die Artefakte des Digitalisierens zu erkennen.

Bild 17: Vergrösserte Darstellung des Wortes "wall". Gut erkennbar besteht der Linienzug nicht ausschliesslich aus schwarzen Pixeln, sondern ist eine Ansammlung von verschieden dunkeln Pixeln. Auch der Hintergrund erscheint nicht weiss sondern grau.
3.2.4 Vorverarbeitung der Einzelbilder
Die einzelnen Bilder einer Bildsequenz werden eingelesen und in einem zweidimensionalen Feld gespeichert. Danach wird das Bild um 180° rotiert und auf die Grenzen der Bounding-Box beschnitten (vgl. Bild 18 oben). Dieser Bildausschnitt wird dann noch mit obengenannter Maske eingeschränkt (vgl. Bild 18 mitte). Hierbei werden alle Bildpunkte in einem Einzelbild belassen, welche in der Maske einem schwarzen Pixel entsprechen. Die anderen Pixel werden weiss eingefärbt (vgl. Bild 18 unten) und sind damit für späteren Komponenten der Erkennung nicht mehr interessant.
| Originalbild |
|
| Dreifach expandierte Maske |
|
| Maskiertes Bild |
|
Bild 18: Das Originalbild (oben) wird durch die Maske (mitte) auf die nähere Umgebung des Schriftzuges reduziert (unten).
Das nun vorliegende Bild wird im nächsten Schritt zur Erstellung des Differenzbilds verwendet. Weil die Maske immer am genau gleichen Ort plaziert wird, bestehen die weissen Flächen auch nach der Differenzbildung immer noch am gleichen Ort. Die Erstellung der Differenzbilder wird also auf die unmittelbare Umgebung des Schriftzuges beschränkt.
3.3 Einschränkung auf Fensterbereich
Wie oben bereits beschrieben wurde wird der Bereich der Einzelbilder beschränkt. Diese Beschränkung betrifft aber nur das Intervall von Einzelbildern aus der Bildsequenz und die Bounding-Box um einen Teil des Schriftzuges. Dieser rechteckige Teil wurde zudem noch maskiert.
Beim Schreiben eines Linienzuges können wir voraussetzen, dass die nachfolgende Stiftposition sehr nahe an der vorherigen Position sein muss. Einzige Ausnahme bilden Linienzüge, welche aus mehreren getrennten Teilen bestehen. Hier kann der Abstand zwischen zwei Positionen des abgesetzten Stifts beim Sprung vom einen zum anderen Linienteil grösser werden (vgl. Bild 19). In Bild 20 sind die Sprünge innerhalb des Wortes "All" und die Sprünge zwischen den Worten durch Pfeile markiert.
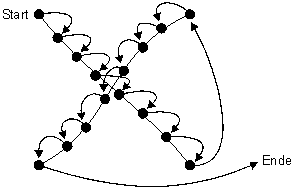
Bild 19: Verbundene Stiftpositionen des Buchstaben "x". Verbindungen auf einem Linienzug sind sehr kurz, doch der Sprung zum nächsten Linienzug kann gross werden.
Um den Suchraum zu begrenzen und falsche Positionen zu vermeiden, werden alle nachfolgenden Operationen nur auf einem quadratischen Bereich ausgeführt, der von nun an einfach Fenster genannt wird. Dieses Fenster ist üblicherweise zwischen 30x30 und 60x60 Pixel gross und hat sein Zentrum an der letzten erkannten Stiftposition. Diese Grösse ist notwendig, damit auch grössere Stiftsprünge von Buchstaben zu Buchstaben oder von Wort zu Wort innerhalb des Fensters zu liegen kommen (vgl. Bild 21).

Bild 20: Sprünge innerhalb des Wortes "All" und Sprünge zwischen den Worten "All", "in" und "all"
Bild 21: Diese Fenstergrösse deckt die Sprünge innerhalb von "All" ab, kann aber den Sprung von "in" zu "all" nicht mehr erfassen.
3.4 Erstellung der Differenzbilder
Zwischen zwei aufeinanderfolgenden Bildern, in diesem Verarbeitungsschritt als maskierter Bildausschnitt vorliegend, wird das Differenzbild erstellt. Im Fall binärer Bilder kann das Differenzbild mit der XOR-Verknüpfung der zwei Bitfelder berechnet werden, welche die binären Bilder repräsentieren. Hier liegen die Bilder aber mit 256 Grauwerten vor. Der Differenzwert eines Pixel wird durch Subtraktion der zwei korrespondierenden Bildpixel nach der Formel von Bild 22 berechnet. Bei der Subtraktion können auch negative Werte auftreten. Diese treten auf, wenn ein dunkler Punkt plötzlich heller wurde. Dies kann mit der Farbe auf dem Blatt Papier nicht geschehen, also ist dieser Teil sicherlich keine Farbe und wird im Differenzbild weiss eingefärbt.
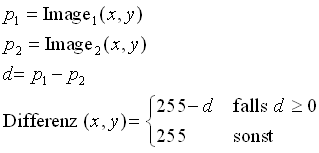
Bild 22: Berechnung des einfachen Differenzbilds zweier Grauwertbilder
Bestandteile des Differenzbilds können auch vom Stift oder von Schatten erzeugt worden sein. Um diese negativen Einflüsse zu beseitigen wird das einfache Differenzbild wie in Bild 24 korrigiert. Hierzu werden eine bestimmte Anzahl nachfolgender Bilder betrachtet. Diese Anzahl wird Lookahead genannt und nimmt üblicherweise Werte zwischen 2 und 5 Bildern an. Verschwindet zwischen zwei nachfolgenden Bildern ein Pixel, d.h. die Helligkeit dieses Pixels nimmt ab, so wird dieses im einfachen Differenzbild eliminiert.

Bild 23: Anpassung eines Differenzbilds aufgrund eines nachfolgenden Bildpaars
Dieses Vorgehen ist korrekt, da die Tinte auf dem Blatt immer bestehen bleibt. Wenn ein Teil des Stifts zuerst fälschlicherweise zu einem dunklen Pixel im einfachen Differenzbild geführt hat und in einem späteren Bild fortbewegt worden ist tritt an dessen Stelle wieder das Weiss des Papiers. Es fand also eine Reduktion der Helligkeit statt, welche erkannt und im einfachen Differenzbild zu einer Korrektur führt. Mathematisch wird dieses Vorgehen in der Formel von Bild 23 beschrieben.
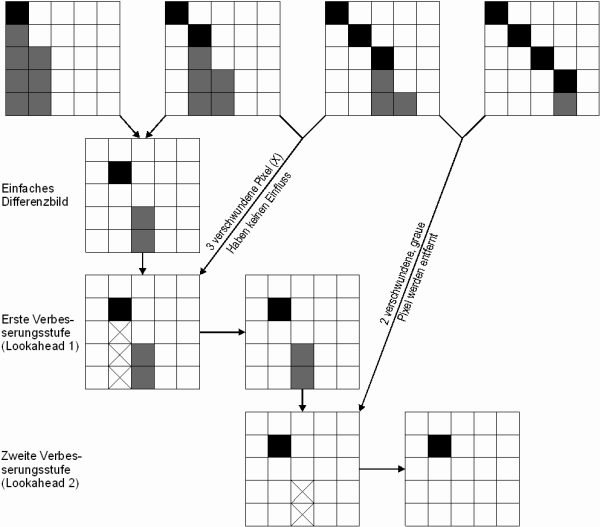
Bild 24: Der graue Stift zeichnet, wie in den obersten vier Bildern illustriert, eine Linie von oben links nach unten rechts. Zwischen den zwei Bildern ergibt sich sowohl ein schwarzer Teil im Differenzbild von der Linie als auch ein grauer Teil vom Stift. Erst die Berücksichtigung der nachfolgenden Bilder eliminiert die überzähligen grauen Teile des Differenzbilds.
3.5 Nachverarbeitung
Alle Bildpunkte, welche je zu einer Erfassung einer Stiftposition führten, werden in einem Summenbild zusammengemischt. Anfangs besteht das Summenbild nur aus weissen Punkten. Beim Verschmelzen der bereits erkannten Punkte im Summenbild mit neu erkannten Punkten werden dunklere Bildpunkte bevorzugt. Hierzu werden alle Punkte, die dunkler als ein Schwellwert sind, noch weiter verdunkelt. Ein neuer Punkt aus dem Differenzbild wird nur dann ins Summenbild aufgenommen, wenn er dunkler ist als sein Pendant im Summenbild.
Bild 25: Verschmelzung des Summenbilds mit neuem Differenzbild
Wenn nun ein neues Differenzbild erstellt wurde, werden in der Nachverarbeitung die im Summenbild vorhandenen Bildpunkte subtrahiert. D.h. von der Helligkeit jedes Punkts im Differenzbild wird die Helligkeit des entsprechenden Punkts im Summenbild gemäss der Formel von Bild 26 subtrahiert.
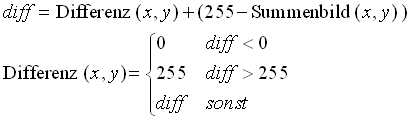
Bild 26: Subtraktion eines Punkts des Summenbilds vom Differenzbild
Zur Verbesserung der Resultate werden zwei kleine Anpassungen vorgenommen:
Bei der temporären Expansion des Summenbilds wird jeder Bildpunkt durch das Resultat einer Funktion auf seiner 8-Nachbarschaft ersetzt. Die Formel von Bild 27 zeigt die Expansion. Es werden sowohl das arithmetische Mittel aller Punkte in der 8-Nachbarschaft als auch der dunkelste Punkt berechnet. Jedem Punkt des Summenbilds wird dann jeweils das arithmetische Mittel dieser zwei Werte zugewiesen.
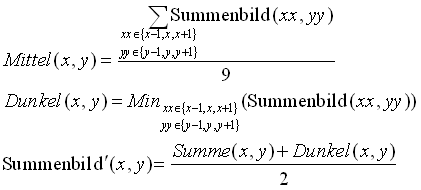
Bild 27: Durch die Expansion der Grauwerte im Summenbild werden die dunklen Bereiche vergrössert
Durch die Anwendung der Formel von Bild 27 wird erreicht, dass die dunklen Bildbereiche des Summenbilds vergrössert werden, dabei aber auch nicht zu dunkel werden (vgl. Bild 28).
Die spezielle Expansion der Graustufen ist notwendig, da nur die dunkelsten Teile eines Schriftzuges Einzug ins Differenzbild finden. Diese Bereiche würden nicht den ganzen Bereich eines nochmals erscheinenden Linienzuges (vgl. "2.5 Nachverarbeitung der Differenzbilder") druch Subtraktion eliminieren. Daher werden die dunklen Teile vergrössert und decken den Schriftzug im Originalbild besser ab.
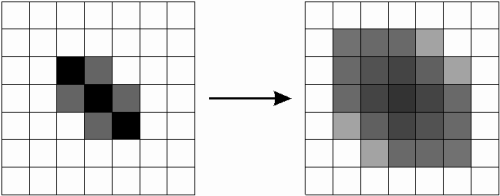
Bild 28: Expansion der Graustufen
Die temporäre Expansion lässt ein schwarzes Pixel aus dem Summenbild "wachsen". Es wird also nicht nur ein einzelnes Pixel als bereits erkannt betrachtet, sondern auch seine unmittelbare Nachbarschaft. Beim Zeichnen eines Schriftzugs wird die nächste Stiftposition meistens unmittelbar an die vorherige anschliessen. Würde die soeben erfasste Differenz sofort ins Summenbild aufgenommen werden, so würden bei der Differenz des nachfolgenden Bildpaars wichtige Teile eliminiert, welche zuerst noch erkannt werden müssen. Wenn die erkannten Pixel wie in Bild 29 mit einer zeitlichen Verzögerung zum Summenbild kumuliert werden, wird die unmittelbare Umgebung der erkannten Stiftposition erst später aus den Differenzbildern eliminiert und dieses Problem kann vermieden werden.
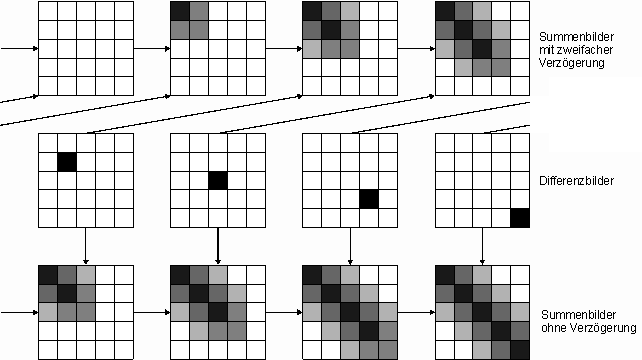
Bild 29: Mischung der Summenbilder mit und ohne Verzögerung
Würden in Bild 29 die Summenbilder (untere Zeile) bereits im nächsten Schritt zur Elimination aus den Differenzbildern (mittlere Zeile) benutzt, dann würden gar keinen neuen Stiftpositionen mehr erfasst. Dank der Verzögerung der Mischung der erkannten Pixel zu den Summenbildern um zwei Schritte (obere Zeile) werden alle Stiftpositionen wie gewünscht erfasst.
Um die Position des Stifts zu bestimmen, muss das grauwertige Differenzbild zuerst in ein Binärbild konvertiert werden. Aus allen schwarzen Punkten in diesem Binärbild wird ein Zentrum ermittelt, welches der Stiftposition entspricht (Pen-Down). Sind keine schwarzen Punkte vorhanden, gibt es kein Zentrum und der Stift war folglich auch nicht auf dem Papier abgesetzt (Pen-Up).
3.6.1 Binärisierung aufgrund des Histogramms
Der Schwellwert für diese Konvertierung wird aus dem Histogramm des Differenzbilds berechnet. Hierzu wird der Algorithmus von N. Otsu [Ots79] auf das Histogramm des Differenzbilds angewendet. Dieser Algorithmus liefert gute Resultate, v.a. auch dann wenn der Unterschied zwischen der Anzahl der dunklen Punkte und der Anzahl der hellen Punkte gross ist. Otsu ist in der Lage einen Schwellwert zu bestimmen auch wenn im Histogramm kein klares Tal erkennbar ist. Nach den Beschreibungen in [Ots79] und [JDS83] funktioniert der Algorithmus von Otsu wie in Bild 30 dargestellt. Bild 31 verdeutlicht die Resultate von Otsu an vier Beispielen.

Bild 30: Berechnung des Schwellwertes eines Bilds aufgrund seines Histogramms nach dem Algorithmus von Otsu
Anhand der vier Beispiele in Bild 31 lässt sich feststellen, dass die Brauchbarkeit der Resultate von Otsu von der Verteilung der Helligkeiten im Histogramm abhängt. In den ersten drei Zeilen ist das ganze Helligkeitsspektrum des Histogramms abgedeckt, wenn oft auch nur sehr schwach. In der letzten Zeile haben alle Bildpunkte in etwa die gleiche Helligkeit und der Schwellwert von Otsu führt zu einer Trennung dieser gleichwertigen Punkte in zwei Klassen, was im binären Bild zu Rauschen führt.
|
|
|
|
|
|
|
|
|
|
|
|
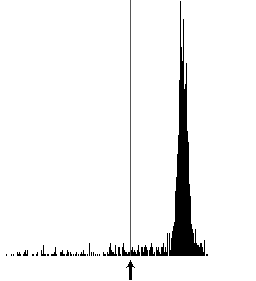
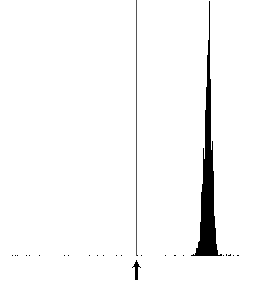
Bild 31: Das Originalbild (links) wird mit einem Schwellwert aus dem Histogramm (mitte, Pfeil zeigt den Threshold) in ein binäres Bild (rechts) konvertiert. Solange das Originalbild sowohl dunkle als auch helle Punkte enthält, befriedigt das Resultat. Sind ausschliesslich helle Punkte (letzte Zeile) enthalten, ist das Resultat unbrauchbar.
Es muss also basierend auf dem Histogramm festgestellt werden, ob dem Resultat von Otsu vertraut wird oder nicht. Eine Möglichkeit wäre, die Bandbreite der Helligkeitswerte im Histogramm zu bestimmen und die Binärisierung nur ab einer bestimmten Grösse dieser Bandbreite durchzuführen. Bei den ersten drei Zeilen von Bild 31 würde diese Bandbreite zwischen 70 - 95% aller Grauwerte betragen; in der letzten Zeile jedoch beträgt die Bandbreite nur gerade ca. 10% aller Grauwerte. Dieser Ansatz hat sich in der Praxis aber nicht bewährt. Der Algorithmus von Otsu liefert neben dem Schwellwert auch die Varianz der Verteilung der Grauwerte im Histogramm zurück. Der Threshold von Otsu wird nur akzeptiert, wenn die Varianz einen bestimmten Grenzwert übertrifft, ansonsten wird keine Binärisierung durchgeführt.
Differenzbild |
Histogramm mit Threshold nach Otsu |
Binäres Bild mit Threshold von Otsu |
|
|
|
|
|
|
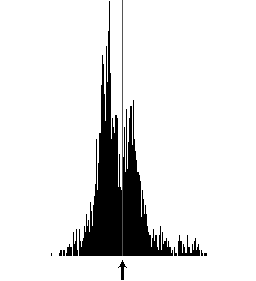
Bild 32: Das obere Resultat von Otsu ist brauchbar (Varianz 1260, Threshold 214), das Untere ist unbrauchbar (Varianz 8, Threshold 249) und führt zu wirren Punkten
Die Differenzbilder bestehen zum grössten Teil aus weissen oder zumindest sehr hellen Punkten. Wenn eine Differenz zwischen zwei Bildern festgehalten wird, so besteht diese zumeist aus wenigen dunklen Punkten (vgl. Bild 32 oben). Wenn ein Differenzbild nur aus hellen Punkten besteht, so wird zwar von Otsu ein Schwellwert geliefert, doch die Varianz des Histogramms ist kleiner als deren Grenzwert. Der Threshold von Otsu wird ignoriert und ein rein weisses Bild ist das Resultat der Binärisierung und damit wird auch kein Punkt erkannt (vgl. Bild 32 unten). Bei einer zu kleinen Varianz wurde also im Differenzbild nichts erkannt und somit auch keine Stiftposition festgestellt; der Stift war also nicht abgesetzt (Pen-Up).
3.6.2 Aufgespannte Fläche
Um die Brauchbarkeit der Binärisierung zu prüfen wird die Fläche der konvexen Hülle der schwarzen Punkte im Fenster (aufgespannte Fläche) berechnet. Diese aufgespannte Fläche wird dann in Relation zur Fläche des Fensters gesetzt. Ist der Anteil der aufgespannten Fläche an der Fläche des Fensters zu gross - in der Praxis hat sich ein Grenzwert von 10% bewährt - wird die Binärisierung als unbrauchbar betrachtet und keine Stiftposition (Pen-Up) erkannt.
Hierbei wird von der Tatsache Gebrauch gemacht, dass der Unterschied zwischen zwei aufeinanderfolgenden Bildern leer oder ein sehr kleines Linienstück resp. Punkt sein sollte. Bei der Aufzeichnung der Bildsequenz werden ca. 20 Bilder pro Sekunde aufgezeichnet. Die Differenz zwischen zwei aufeinanderfolgenden Bildern wird also in 1/20 Sekunde geschrieben. In solch kurzer Zeit ist es unmöglich, dass der Stift grosse Mengen an Farbe weit verteilt auf das Blatt auftragen kann. Bei einer sehr hohen Geschwindigkeit des Stifts ist einen lange Linie möglich. Eine lange Linie hat aber immer noch, wie das mittlere Beispiel in Bild 33 zeigt, eine geringe Fläche und wird akzeptiert. Wenn eine zu grosse aufgespannte Fläche vorliegt, so ist dies entweder auf eine starke Verstreuung der einzelnen Punkte (vgl. Bild 33 rechts) oder auf einen Ausreisser (vgl. Bild 33 mitte) zurückzuführen. Im Normalfall (vgl. Bild 33 links) liegen alle schwarzen Punkte des binärisierten Differenzbilds nahe beisammen und spannen eine kleine Fläche auf.
|
|
|
Aufgespannte Fläche deckt |
Aufgespannte Fläche deckt |
Aufgespannte Fläche deckt |
Bild 33: Die aufgespannten Flächen von drei verschiedenen Punktmengen
Zunächst wird die Bounding-Box aller schwarzen Punkte im Fenster des binären Bilds bestimmt. Ist die Fläche dieser Bounding-Box bereits klein genug, so ist es sicherlich auch die aufgespannte Fläche, welche ganz in der Bounding-Box liegt. Hierdurch muss nur die Bounding-Box (Zeitkomplexität ist O(n)) bestimmt werden, was effizienter ist als die Berechnung der aufgespannten Fläche. Sollte die Bounding-Box zu gross sein, muss die aufgespannte Fläche exakt bestimmt werden, da sie wie in Bild 34 viel kleiner als die Bounding-Box sein kann.
|
Bild 34: Sieben schwarze Bildpunkte inklusive umfassender Bounding-Box und der aufgespannten Fläche. In diesem Fall ist die aufgespannte Fläche wesentlich kleiner als die Fläche der Bounding-Box.
Zur Berechnung der aufgespannten Fläche wird zunächst durch alle schwarzen Punkte im Fenster ein sternförmiges Polygon gelegt. Von diesem wird dann die Konvexe Hülle mit dem Graham’s Scan (vgl. [Sed92, Seiten 417-422], [Las96, Seiten 141-145]) erstellt (Zeitkomplexität ist O(n log n)). Die Konvexe Hülle ist wiederum ein Polygon, von dem mit der Formel von Bild 35 die Fläche berechnet werden kann. Die Fläche dieses Konvexen Polygons entspricht dann der aufgespannten Fläche und wird mit der Fläche des Fensters verglichen. Ist die aufgespannte Fläche zu gross, werden im binären Bild alle schwarzen Punkte durch weisse ersetzt: Es findet also keine Erkennung einer Stiftposition statt.
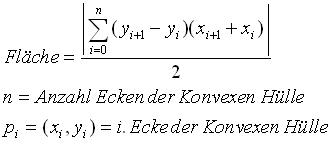
Bild 35: Berechnung der Fläche eines Konvexen Polygons (6)
3.6.3 Einfacher Mittelpunkt
Am einfachsten lässt sich das Zentrum der schwarzen Punkte im Fensterbereich, ab nun Punktmenge genannt, durch das arithmetische Mittel bestimmen. Hierbei entspricht die x-Koordinate des Zentrums dem arithmetischen Mittel aller x-Koordinaten der schwarzen Punkte im Fenster und die y-Koordinate dem artithmetischen Mittel aller y-Koordinaten. Die exakte Formel ist in Bild 36 aufgeführt.
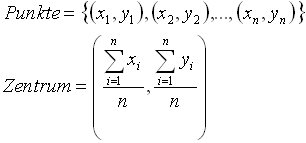
Bild 36: Berechnung des Zentrums von Punkten mit dem arithmetischen Mittel
Solange alle schwarzen Punkte nahe beisammen liegen ist das Resultat gut. Wenn nun aber ein einziger Punkt wie in Bild 37 von den fünf beieinanderliegenden Punkten entfernt ist, wird das Zentrum zu stark vom Ausreisser angezogen und das Resultat befriedigt nicht mehr. Bei der Berechnung des arithmetischen Mittelpunkts haben einzelne, weit entfernte Punkte ein zu starkes Gewicht. Daher ist diese Methode für die vorliegende Anwendung uninteressant.
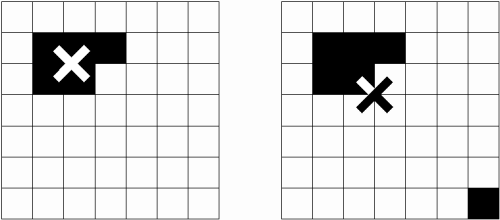
Bild 37: Liegen alle Punkte nahe beisammen (links) ist das Zentrum gut bestimmt. Ein einzelner Ausreisser (rechts) kann das Resultat aber bereits zu stark negativ beeinflussen.
3.6.4 Iterativer Mittelpunkt
Die Resultate des arithmetischen Mittels können durch iterative Anwendung verbessert werden. Hierbei wird zuerst der einfache Mittelpunkt nach Formel von Bild 36 bestimmt. In weiteren Iterationsschritten - zwei bis vier haben sich als genügend erwiesen - wird wieder ein arithmetisches Mittel bestimmt, wobei die Punkte umgekehrt proportional zum Abstand vom vorherigen Zentrum gewichtet werden (vgl. Formel in Bild 38).
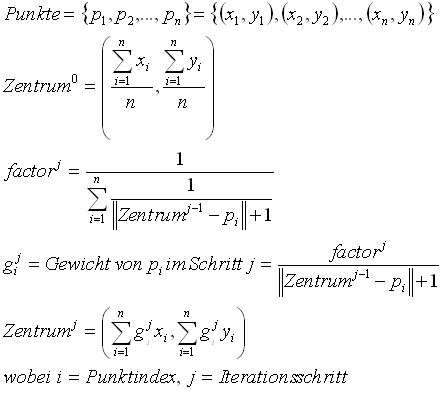
Bild 38: Iterative Berechnung des Zentrum von Punkten mit dem arithmetischen Mittel. Die Punkte werden umgekehrt proportional zum Abstand vom Zentrum gewichtet.
Durch die Gewichtung der einzelnen Punkte mit dem Abstand vom Zentrum des vorherigen Schritts werden Punkte, die bereits nahe am Zentrum liegen, bevorzugt und beeinflussen die Lage des Zentrums stärker als vereinzelte Punkte welche weit weg vom Zentrum liegen. Dies wird in den drei Beispielen von Bild 39 deutlich sichtbar.

Bild 39: Beispiel für die iterative Berechnung des Zentrums. Das linke Beispiel entspricht dem einfachen Mittelpunkt. Nach einem Iterationsschritt (mitte) liegt das Zentrum schon besser und schliesslich mit zwei Iterationschritten (rechts) richtig.
3.6.5 Mittelpunkt durch Median-Methode
Eine weitere Methode zur Bestimmung des Zentrums einer Punktmenge basiert auf der Berechnung eines Medians (7). Hierbei wird der Median aller x-Koordianten und der Median aller y-Koordianten der Punkte bestimmt. Wie in Bild 40 gezeigt wird bestimmen diese zwei Mediane die x- und y-Koordinaten des Zentrums der Punktmenge.
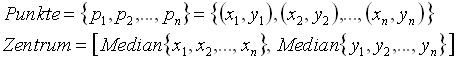
Bild 40: Bestimmung des Zentrums durch die Mediane der x- bzw. y-Koordinaten
Die Median-Methode liefert gute Resultate. Die Berechnung ist aufgrund der notwendigen Sortierung der Koordinaten nicht mit einer kleineren Zeitkomplexität als O(n log n) zu bewerkstelligen. Die Median-Methode liefert transparentere und einleuchtendere Resultate als die iterative Methode. Das Zentrum besteht bei der Median-Methode aus zwei Koordinaten welche jeweils bereits in der Punktmenge aufgetaucht sind. Nachteilig ist aber, dass die Kombination zweier solcher Koordinaten einen neuen Punkt erzeugen kann (vgl. Bild 41, rechter Fall), welcher nicht in der Punktmenge exisitiert.
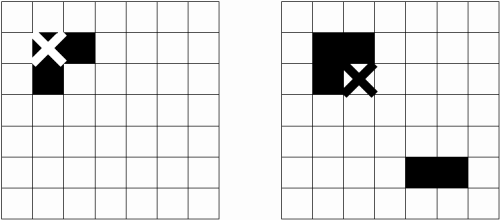
Bild 41: Sowohl im linken Fall ohne Ausreisser, als auch im rechten Fall mit Ausreissern, wird das Zentrum nahe bei den drei dominierenden Punkten gewählt.
3.6.6 Mittelpunkt durch Neighbour-Methode
Alle bisher vorgestellten Methoden haben den grossen Nachteil, dass das Zentrum ein Punkt sein kann, der nicht in der Punktmenge enthalten ist. Vorteilhaft wäre es, wenn ein Punkt aus der Punktmenge zum Zentrum dieser Menge bestimmt würde. Hierzu eignet sich die Neighbour-Methode, welche den zentralen Punkt aufgrund seiner Distanzen zu den anderen Punkten und seiner 8-Nachbarschaft bestimmt.
Bei der Neighbour-Methode wird für jeden Punkt die Summe der Abstandsquadrate (8) zu allen anderen Punkten in der Punktmenge berechnet. Diese Abstandsquadratsumme wird dann noch durch die Anzahl Punkte in der 8-Nachbarschaft dividiert (vgl. Formel von Bild 42). Die Zeitkomplexität der Neighbour-Methode beträgt O(n2).
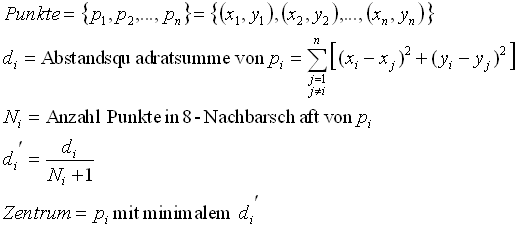
Bild 42: Bestimmung des zentralen Punkts aufgrund seiner Lage zu allen anderen Punkten und seiner 8-Nachbarschaft.
Dank der Division durch die Anzahl Nachbarn wird erreicht, dass alleinstehende Punkte benachteiligt werden und Punkte bevorzugt werden, welche von anderen Punkten umgeben sind. Dies ist beabsichtigt, denn es soll wie in Bild 43 ein Punkt innerhalb des grössten dunklen Flecks als Zentrum gewählt werden.
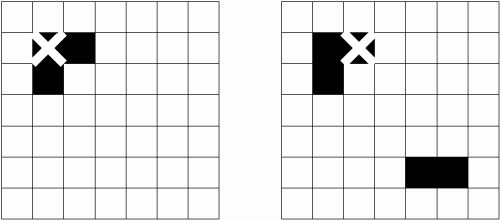
Bild 43: Zwei Beispiele für die Bestimmung des Zentrums mit der Neighbour-Methode
3.6.7 Vergleich der Methoden
Die Resultate der Neighbour-Methode können in dieser Arbeit am besten verwendet werden. Die Hauptvorteile liegen in der schwachen Berücksichtigung von einzelnen Ausreissern in der Punktmenge und darin, dass ein bestehender Punkt zum Zentrum der Punktmenge auserkoren wird und nicht ein neuer Punkt generiert wird. Auch die Median-Methode hat sich bewährt. Ihr einziger Nachteil ist die Generierung von neuen Punkten. Zum Vergleich der Methoden sei auf Bild 11 verwiesen.
3.7 Verbesserung und Ausgabe der Positionen
Der bisher erläuterte Teil des Datenflusses durch das System liefert eine Sequenz von Positionen. Diese Positionen entsprechen entweder einem Punkt auf dem Platt Papier (Pen-Down) oder sind leere Positionen (Pen-Up). Diese Sequenz lässt sich mit einfachen Mitteln der linearen Interpolation noch verbessern. Dabei werden kurze Lücken zwischen zwei Punkten durch linear interpolierte Punkte verbunden. Zu lange Verbindungen zwischen zwei aufeinanderfolgenden Punkten werden als Fehler interpretiert und durch eine eingefügte leere Position getrennt. Die exakte Funktionsweise der Interpolationsroutine ist in Bild 44 beschrieben.
|
Bild 44: Funktionsweise der Interpolationsroutine in Pseudocode
In Bild 45 werden zwei Beispiele gezeigt bei denen die Interpolationsroutine neue Punkte einführt. Im ersten Beispiel besteht eine Lücke von einer Position zwischen zwei nahen Punkten. Die Lücke wird als Kreis an der möglichen Stelle auf dem Linienzug dargestellt. Die Lücke zwischen den zwei Punkten wird durch einen linear interpolierten Punkt ersetzt. Im zweiten Beispiel findet das Gleiche für eine Lücke von zwei Positionen statt.

Bild 45: Erfolgreiche Interpolation fügt neue Punkte ein
Die Lücke von drei Punkten im ersten Beispiel von Bild 46 kann nicht geschlossen werden, da die Distanz zwischen den zwei vorhandenen Punkten zu gross ist. Im unteren Beispiel wird schliesslich die überlange, direkte Verbindung zwischen zwei aufeinanderfolgenden Punkten getrennt.
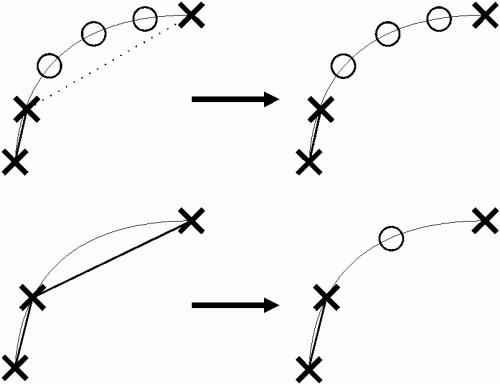
Bild 46: Die Interpolationsroutine kann zu lange Stücke nicht überbrücken, bestehende überlange Verbindungen werden sogar getrennt.
Diese verbesserte Punktliste wird schliesslich in einem Online-Format ausgegeben. Zur Auswahl stehen entweder ein systemeigenes Format oder das Online-Format des Handschrift-Erkenners der ETHZ. Im systemeigenen Format werden pro Textzeile ein Index und die Koordinaten des Punkts ausgegeben. Bei einer Lücke wird nur der Index ausgegeben. Das ETHZ Online-Format repräsentiert eine LISP-Matrix. Die erste Zeile enthält die Anzahl Worte in der Datei. Die zweite Zeile enthält die ASCII-Repräsentation des Wortes. Danach folgen in eckigen Klammern die Punkte. Pro Punkt werden die Koordinaten und ein Zeitstempel angegeben. Lücken werden nicht ausgegeben. Details zum Aufbau dieser Formate können sowohl dem "Kapitel 4 – Implementation" als auch dem "Anhang E – ETHZ-Handschrifterkenner" entnommen werden.
1) SunVideo ist die Software-Bibliothek von SUN, welche zu deren SunVideo-SBus-Karte für Bilderfassung und Komprimierung von Videosignalen geliefert wird. Das Programm SunVideo dient dazu, die Videoquelle als MPEG-1 Datei abzuspeichern. Weitere Informationen zur Erfassung von Video-Daten mit SunVideo können im im Anhang A und [Sun94] gefunden werden.
2) PPM ist die Abkürzung für "portable pixmap file format". PPM beschreibt ein sehr einfaches Format um Bilddateien abzuspeichern. Es besteht aus einer Magic Number, welche das Format des Bilds beschreibt, der Bildbreite und –höhe, der Farbtiefe und der Bilddaten. Die Bilddaten werden entweder als ASCII-Text oder als rohe Byte-Werte abgespeichert. Die dazugehörige Programmbibliothek PBMPLUS (Extended Portable Bitmap Toolkit, 1991) stammt von Jef Poskanzer (jef@well.sf.ca.us).
3) mpeg2decode ist ein Programm der MPEG Software Simulation Group (MPEG-L@netcom.com, ftp://ftp.netcom.com/pub/cfogg/mpeg2), welches MPEG-1 und MPEG-2 Videodateien in verschieden Bildformaten wie TGA, X11 oder PPM konvertieren kann. Die erzeugte Sequenz von Einzelbildern kann dabei aufsteigend numeriert werden.
4) Das UNIX Kommandozeilen-Programm ppmtopgm wandelt TrueColor-PPM-Bilder in Graustufenbilder um. Hierbei werden die 3 Farbkomponenten folgendermassen zu einem Grauwert quantisiert:0.299 * Rot + 0.587 * Grün + 0.114 * Blau.
5) Die 4-Nachbarschaft eines Pixels besteht aus den Pixeln oberhalb, unterhalb, links und rechts vom Pixel im Zentrum. Bei der 8-Nachbarschaft werden zusätzlich noch die Pixel oben-links, oben-rechts, unten-links und unten-rechts in die Nachbarschaft miteinbezogen.
6) Die Quelle der Berechnung der Fläche eines konvexen Polygons ist leider nicht bekannt. Mir wurde diese Formel von Philipp Grünig zugetragen. Er verwendete diese Formel in einem HP-48er-Programm zur Berechnung der Statik von Metallträgern. Hierbei musste er die Fläche von polygonalen Querschnitten mit darin enthaltenen polygonalen Löchern berechnen.
7) Der Median einer Menge ist als der mittlere Punkt der sortierten Menge definiert. Der Median der Menge {6,2,8,5,3} ist der mittlere Punkt der sortierten Menge {2,3,5,6,8}, also 5. Das arithmetische Mittel wäre 4.8.
8) Die Verwendung der Abstandsquadrate vermeidet die Berechnung der Quadratwurzel und hat auf die Bestimmung des Punkts mit der kleinsten Abstandssumme zu allen anderen Punkten keinen Einfluss.