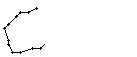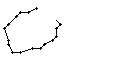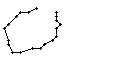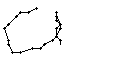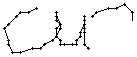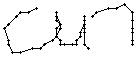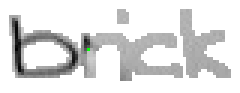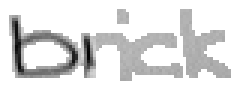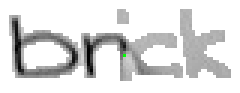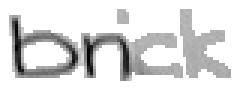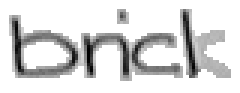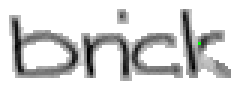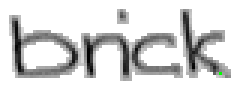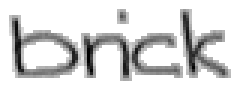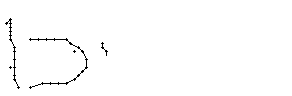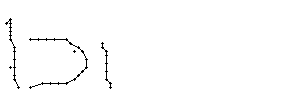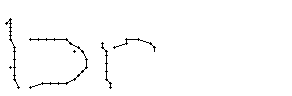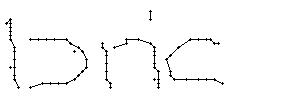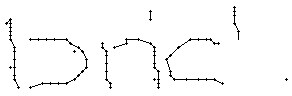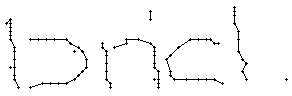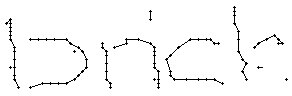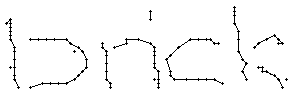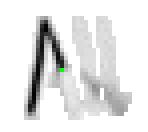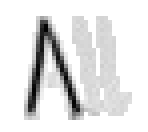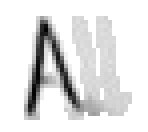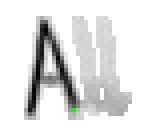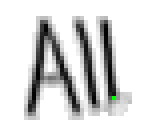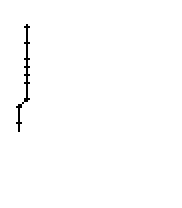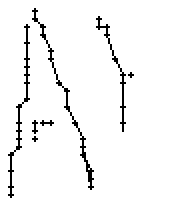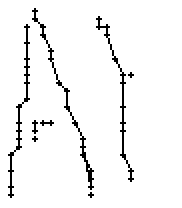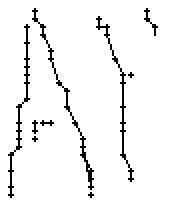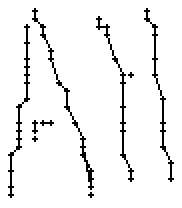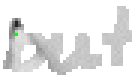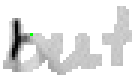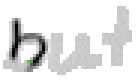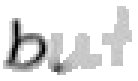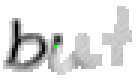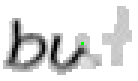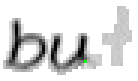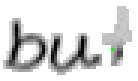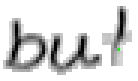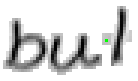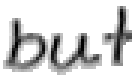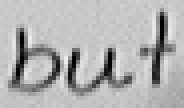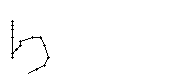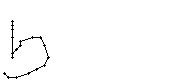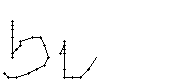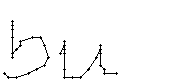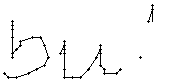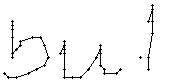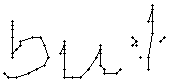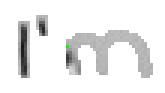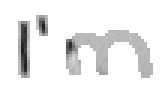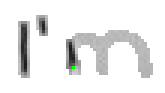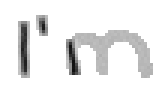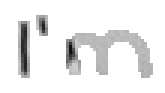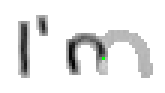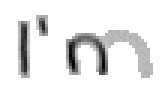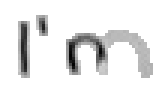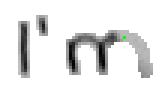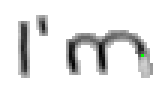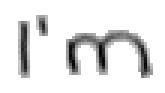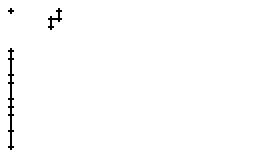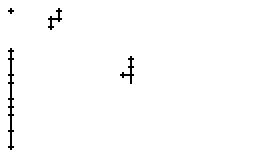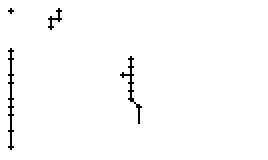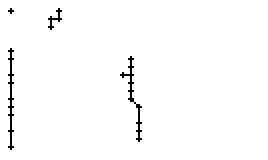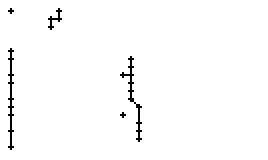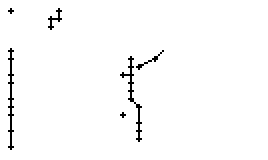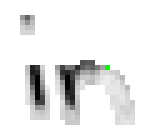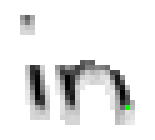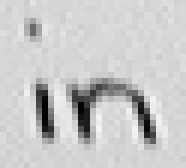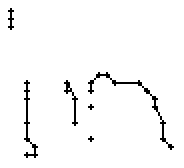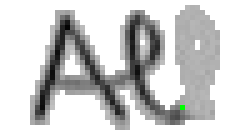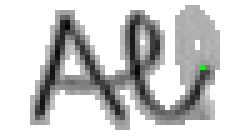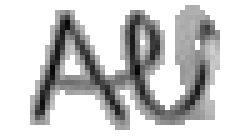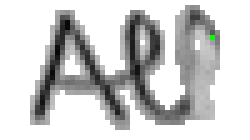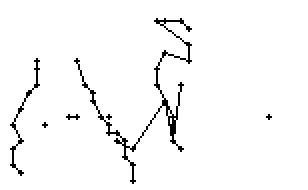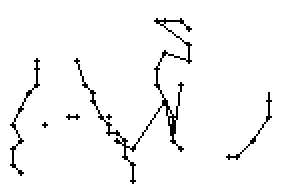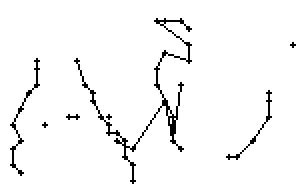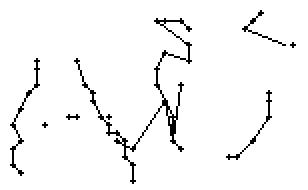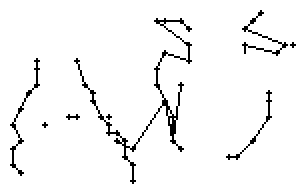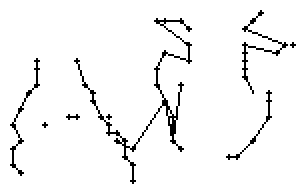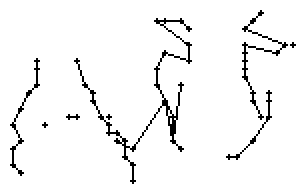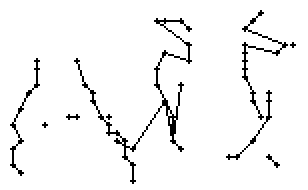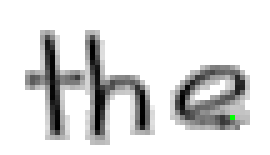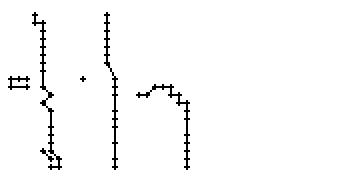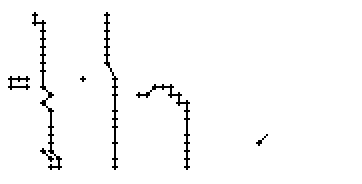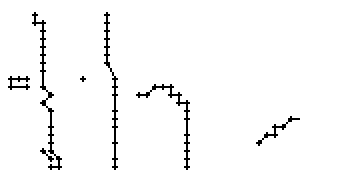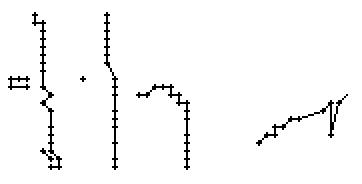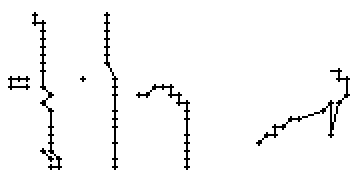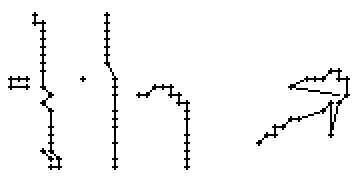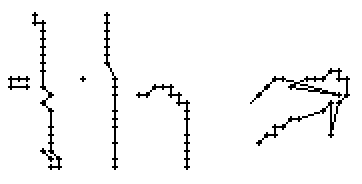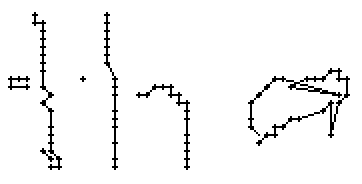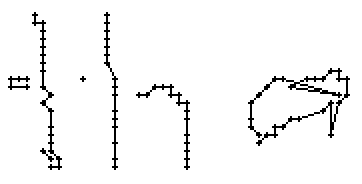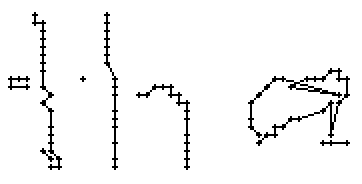
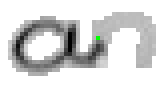
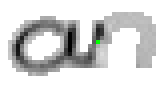
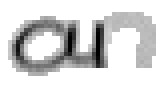
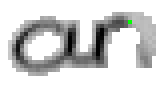
Kapitel 5 - Resultate
In diesem Kapitel werden die erzielten Resultate des vorliegenden Systems zur Erfassung von Online-Daten vorgestellt. Zuerst werden die Testdaten vorgestellt, welche als Videodateien einzelner geschriebenen Textzeilen vorliegen. Aus dieser grossen Menge von Testdaten werden einzelne Worte ausgesucht; hierbei werden sowohl gut erfasst Worte als auch solche mit Problemen gewählt. Bei den problematischen Worten wird die Fehlerursache analysiert. Mögliche Lösungsansätze werden in Kapitel 6 skizziert. Schliesslich werden die Resultate der Tests mit dem Online-Handschrifterkenner der ETHZ gezeigt.
5.1 Verwendete Eingabesequenzen
Die Eingabesequenzen stammen von zwei Schreibern und bestehen je aus sieben englischen Sätzen. Diese sieben Sätze ergaben, gesamthaft für beide Schreiber, die 28 brauchbaren Textzeilen von Bild 63, welche je in einer Videodatei abgespeichert sind. Im Detail werden die Eingabedaten im Anhang C vorgestellt.
"Please report bugs to" "The quick brown
fox" "I’m a student
in comp. science" "And remember,
it’s" "There is no
sadder" "This diploma work
tries" "All in all
it’s just an-" |
Bild 63: Die Testdaten bestehen aus sieben Sätzen mit je ein bis drei Textzeilen
Beim Schreiben dieser Sequenzen wurde darauf geachtet, dass alle notwendigen Restriktionen, wie sie in "2.2 Erfassung der Bildsequenz" aufgestellt wurden, erfüllt sind. Dies konnte in den meisten Fällen erfüllt werden, doch vier Problemgruppen liessen sich, wie weiter hinten in "5.4 Probleme beim Erfassen" erläutert wird, nicht vermeiden. Trotz dieser Probleme konnte die Hälfte der Worte gut erfasst werden. Diese Resultate werden in "5.3 Resultate der verarbeiteten Wörter" vorgestellt.
5.2 Parameter der Erfassungsroutine
Sehr wichtig für eine gute Erfassung der Stiftpositionen aus der Eingabesequenz ist die richtige Festlegung einer Reihe von Systemparametern. Leider gibt es zu diesen Parametern keine optimale Einstellung, welche für alle möglichen Eingabesequenzen gute Resultate liefern würde. Nachfolgend werden die Auswirkungen dieser Parameter erläutert, sinnvolle Wertebereiche angegeben und mögliche Anpassungen bei bestimmten Erfassungsproblemen aufgezeigt.
|
Bild 64: Konfigurationsdatei für das Wort "an" aus dem letzten Satz von Bild 63.
Diese Parameter werden in einem Konfigurationsfile (1) gespeichert und steuern die Verarbeitung der Eingabesequenzen durch die Programme HTMLreport.pl (2) und mpeg2points (3). Eine solche Konfigurationsdatei ist in Bild 64 abgebildet.
Die Parameter der Konfigurationsdatei werden nachfolgend aufgelistet und erklärt:
Word wird von der textuellen Repräsentation des Worts gefolgt. Diese wird später bei der Verarbeitung mit dem ETHZ-Erkenner benötigt um die Korrektheit der Erkennung festzustellen.
Report legt fest wo die Resultate (Liste der Punkte als Textdatei und Debug Informationen) gespeichert werden sollen. Diese Daten werden in dem Verzeichnis gespeichert, welches hinter dem Parameter report_dir aufgeführt ist. In diesem Verzeichnis wird ein Unterverzeichnis mit dem Namen der Sequenz (report_name) erstellt.
Source bestimmt den Speicherort der Eingabesequenz. Der Parameter source_dir legt das Basisverzeichnis der Sequenz fest. In diesem Verzeichnis werden Dateien gelesen welche mit source_name beginnen und aufsteigend numeriert sind (Zahl mit source_digits Ziffern).
Window legt die Bounding-Box fest. Dem Parameter folgen die Koordinaten zweier gegenüberligender Ecken dieses Rechtecks.
Start Index des ersten Bilds des Zeitintervalls der Sequenz.
End Index des letzten Bilds des Zeitintervalls der Sequenz.
Alle oben beschrieben Parameter hängen direkt von den Eingabedaten ab und können vom Benutzer bequem in der Anwendung viewimages (4) erfasst werden. Die interessanteren Parameter können auch in viewimages festgelegt werden, doch diese Werte bedürfen meistens noch einer spezifischen Optimierung basierend auf den Resultaten der Eingabesequenz. Die Komponenten in denen diese Parameter Anwendung finden werden in Kapitel 3 beschrieben. Nachfolgend sind die weiteren Parameter aufgelistet und werden beschrieben:
Methods bestimmt die zur Bestimmung der Stiftpositionen zu verwendenden Routinen. In Bild 64 wird die Position sowohl mit der Median-Methode als auch mit der Neighbour-Methode erfasst. Dies hat zwei verschiedene Resultate zur Folge welche in der erstellten Übersicht verglichen werden können.
Winsize legt die Seitenlänge des quadratischen Fensters fest. Dieses Fenster hat seinen Mittelpunkt auf der letzten erkannten Stiftposition und innerhalb des Fensters wird nach der neuen Stiftposition gesucht. Bei der Festlegung der Fenstergrösse muss beachtet werden, dass das Fenster genug gross gewählt wird um den Bereich vom Ende des einen Linienzuges zum Anfang des nächsten Linienzuges abzudecken.
Bei den Testdaten haben sich Fenstergrössen von 30 bis 40 bewährt. Falls die Erfassung von Stiftpositionen am Ende eines Linienzuges plötzlich beendet werden sollte, muss das Fenster vergrössert werden. Andererseits sollte die Fenstergrösse auch möglichst klein gewählt werden, damit die neue Stiftposition lokal und nahe gesucht wird und es zu möglichst wenigen Störquellen kommen kann.
Lookahead bestimmt die Anzahl nachfolgender Bilder welche bei der Erstellung des Differenzbilds berücksichtigt werden. Dadurch werden fälschlich erkannte bewegliche Teile (z.B. Stift, Hand oder Schatten) aus den Differenzbildern eliminiert. Die Einstellung dieses Parameters ist von vielen Faktoren abhängig, hauptsächlich aber von der Breite des Stifts und der Geschwindigkeit mit welcher der Stift bewegt wird.
Parameterwerte von 2 bis 5 erwiesen sich als brauchbar. Sollten oft falsche Stiftposition erfasst werden, dann kann es an einem zu kleinen Lookahead liegen und der Parameterwert sollte erhöht werden. Wird gar keine Stiftposition mehr erkannt oder nur noch vereinzelte, dann wurde der Wert zu hoch eingestellt.
Otsuvariance steuert die Akzeptanz der Resultate des Algorithmus von Otsu. Falls die Varianz des Histogramms tiefer als diese Schranke ist, wird angenommen, dass das Differenzbild nur aus hellen Punkten besteht. Es wird keine Stiftposition erkannt. Je tiefer diese Schranke ist, desto stärker werden helle Graustufen als schwarze Punkte anerkannt.
Grenzwerte der Otsuvariance von 30 bis 40 haben sich in der Praxis bewährt. Zur korrekten Bestimmung der notwendigen Otsuvariance ist es empfehlenswert, die Bildsequenz mit den Debuginformationen zu berechnen und anhand der Varianz der einzelnen Differenzbilder Rückschlüsse auf den Schwellwert zu ziehen. Falls in hellen Differenzbildern schwarze Punkte erkannt werden, dann ist der Parameter Otsuvariance zu tief eingestellt. Otsuvariance sollte ein wenig höher als die Varianz des Histogramms des hellen Differenzbilds gesetzt werden. Zu hohe Parameterwerte führen zur Nichterfassung von Stiftpositionen in Differenzbildern, welche Ansammlungen von grauen Punkten aufweisen, und somit zu Lücken in den Linienzügen.
Masksize bestimmt die Dicke der Maske, welche in der Vorverarbeitung dazu dient die Linienzüge aus den Originalbildern zu extrahieren. Die ideale Maske sollte den gesamten Linienzug in allen Einzelbildern enthalten und nur minimale Teile des Bildhintergrundes.
Maskengrössen von 2 bis 5 führen zu guten Resultaten. Bei den meisten Bildsequenzen reicht eine Maskengrösse von 2 aus. Sollten aber in einzelnen Bildern der Sequenz Teile des Schriftzuges ausserhalb der Maske liegen, muss sie vergrössert werden. Zudem sollte die Maske die Linien des Schriftzuges in ihrer vollen Breite bis zum Übergang in den Hintergrund abdecken. Eine zu grosse Maske erweitert den Suchraum für Stiftpositionen unnötig und kann zu falschen Positionen führen. Die Maske wird bereits im Programm viewimages angezeigt und kann hier bequem über die ganze Bildsequenz hinweg geprüft werden.
Area bestimmt den maximal zulässigen Anteil der Konvexen Hülle der schwarzen Punkte (aufgespannte Fläche) aus dem Differenzbild an der Fenstergrösse. Ist die Fläche der Konvexen Hülle der schwarzen Punkte zu gross, wird angenommen, dass ein Fehler in der Bestimmung des Schwellertes durch Otsu vorliegt und keine Stiftposition erkannt.
Der Wert von 0.1 hat sich in der Praxis bewährt. Anpassungen im Bereich von 0.05 bis 0.25 können je nach Fall Sinn machen. Hierzu sollten aber die Debuginformationen des Programmes mpeg2points hinzugezogen werden. Dort sind sowohl die Differenzbilder als auch das jeweilige Verhältnis zwischen der aufgespannten Fläche und der Fensterfläche aufgeführt. Aufgrund dieser Daten kann dann die Einstellung des Parameters Area verbessert werden.
Interpolate Die Parameter intermin, intermax und intergap steuern die Verbesserung der erfassten Stiftpositionen. intermin legt die maximale Distanz zwischen zwei Stiftpositionen fest welche interpoliert werden darf. intergap bestimmt das Maximum mit Interpolation überbrückbarer Lücken in der Liste der Stiftpositionen. intermax beschränkt die maximale Länge einer bestehenden Verbindung zwischen zwei Stiftpositionen.
Bei den Testbeispielen haben sich Werte von 5 bis 8 für intermin, 5 bis 10 für intermax und 2 bis 5 für intergap bewährt. Diese Parameter müssen in dieser Konfigurationsdatei noch gar nicht definitiv bestimmt sein. Am besten werden diese Parameter in der Applikation viewpoints (5) bestimmt und getestet.
Die Menge der Parameter mag zwar erschrecken, doch die Parameter Winsize und Masksize lassen sich vom Benutzer aus den Eingabedaten ableiten und Area kann konstant auf 0.1 gehalten werden. Die Interpolationsparameter können interaktiv eingestellt werden und ihr Einfluss ist sofort ersichtlich. Nur die Einstellungen der Parameter Otsuvariance und Lookahead sind weniger direkt ersichtlich. Zum Anpassen dieser Parameter können einerseits die Debuginformationen helfen, andererseits kommt man nicht umhin verschiedene Werte zu testen.
5.3 Resultate der verarbeiteten Wörter
Hier werden exemplarisch vier Wörter vorgestellt, welche verarbeitet wurden und zu guten Online-Daten konvertiert werden konnten. Zwei dieser Wörter stammen von Christina Lisser, die anderen zwei vom Autor dieser Diplomarbeit. Es mag erstaunen, dass v.a. kurze Worte ausgewählt wurden. Dies ist aber darin begründet, dass gewisse Buchstaben Probleme bereiten. Auf diese Probleme bei Buchstaben, wie z.B. "l" oder "e", wird im Abschnitt "5.4 Probleme beim Erfassen" eingegangen. Hierdurch fallen alle Worte mit diesen Buchstaben weg und es bleiben v.a. kurze Worte übrig, da bei diesen die Wahrscheinlichkeit einen problematischen Buchstaben zu enthalten geringer ist.
Es wird versucht, die Dynamik der Bildsequenzen möglichst gut darzustellen. Hierzu wird zuerst von jedem Wort die entsprechende Bildsequenz dargestellt. Die volle Sequenz würde pro Wort aus 80 bis 200 Bilder bestehen, was sich hier unmöglich abbilden lässt. Daher werden nur jedes x-te Bild der Eingabesequenz in einer Tabelle dargestellt. Weiter werden die verwendeten Parameter für die Erfassung mit dem Programm mpeg2points aufgezeigt und schliesslich die daraus resultierenden Online-Daten. Die Online-Daten bestehen aus einer Liste von Stiftpositionen zu bestimmten Zeitpunkten. Eine solche Liste wäre für den Leser nicht praktisch zu interpretieren. Daher werden die Punkte der Online-Daten zu Linienzügen verbunden. Die Entstehung des Linienzuges, welcher zum Schluss das Wort repräsentiert, wird an signifikanten Positionen festgehalten und abgebildet. Dabei entsteht eine tabellarische Darstellung.
5.3.1 Wort 1: an
Das Wort "an" (6) wurde von Christina Lisser geschrieben und entstammt dem letzten Satz von Bild 63. Dieses Wort würde eigentlich "another" heissen, doch da es getrennt wurde, ist der Teil vor dem Trennzeichen als einzelnes Wort verwendet worden.
|
|
|
|
|
|
|
|
|
|
|
|
Bild 65: Jedes sechste Einzelbild der Bildsequenz des Wortes "an"
Folgende Parameter wurden bei der Erfassung der Stiftpositionen verwendet:
| Parameter | Wert |
| Masksize | 2 |
| Winsize | 40 |
| Area | 0.1 |
| Lookahead | 3 |
| Otsuvariance | 40 |
| Method | Neighbour |
| Intermin, Intermax, Intergap | 5, 10, 3 |
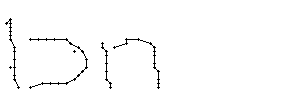
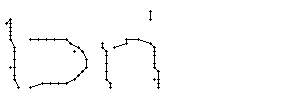
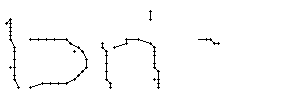
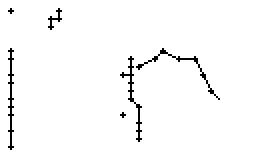
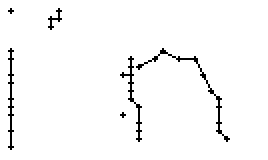
Als Spezialität in diesem Wort ist zu bemerken, dass der erste senkrechte Strich beim Buchstaben "n" nur einmal erfasst wurde. In Wirklichkeit wurde diese Strecke vom Stift sowohl beim Abstrich als auch beim Aufstrich mit anschliessendem Bogen gezeichnet. Da die Tinte beim zweiten Mal auf die bestehende Tinte aufgetragen wurde, konnte aus der Sicht der Kamera keine Veränderung festgestellt werden. Neue Tinte wurde erst wieder erkannt, als begonnen wurde den horizontalen Bogen nach rechts zu zeichnen. Das "n" besteht also aus einem Abstrich und einem davon abgetrennten horizontalen Bogen mit anschliessendem Abstrich.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Bild 66: Ablauf der Erfassung des Wortes "an"
5.3.2 Wort 2: brick
Das Wort "brick" (7) wurde von Christina Lisser geschrieben und entstammt dem letzten Satz von Bild 63.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Bild 67: Jedes elfte Einzelbild der Bildsequenz des Wortes "brick"
Folgende Parameter wurden bei der Erfassung der Stiftpositionen verwendet:
| Parameter | Wert |
| Masksize | 2 |
| Winsize | 40 |
| Area | 0.1 |
| Lookahead | 3 |
| Otsuvariance | 40 |
| Method | Neighbour |
| Intermin, Intermax, Intergap | 5, 9, 6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Bild 68: Ablauf der Erfassung des Wortes "brick"
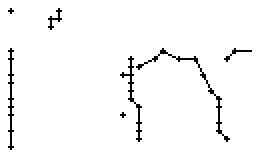
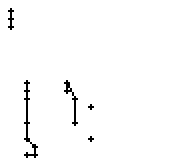
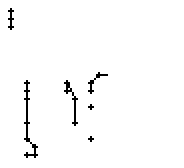
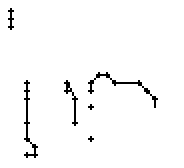
Wie schon beim "n" vom vorherigen Wort wird ein Linienstück, welches vom Schreiber zweimal übereinander geschrieben wird, nur beim ersten Mal als Linienzug erfasst. So besteht das "r" in den Online-Daten aus einem Abstrich und einem horizontalen Bogen nach rechts. Weiter können gewisse Linienstücke, welche in Wirklichkeit ein anderes Linienstück berühren, nicht genau so erkannt werden. Der Buchstaben "b" besteht also aus zwei Stücken: Dem senkrechten Strich und dem "Bauch". Der Bauch würde eigentlich exakt an den senkrechten Strich angrenzen. Bei der Erfassung der Stiftpositionen werden die Mittelpunkte der schwarzen Punkte im Differenzbild gefunden. Da der senkrechte Strich eine Dicke von ca. vier Pixel hat und bereits erkannte Pixel nicht neu erkannt werden ist die erste Position des "Bauches" einige Pixel vom senkrechten Strich entfernt. Eine Illustration hierzu kann in Bild 69 gefunden werden.
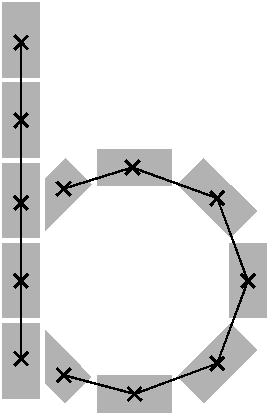
Bild 69: Erfasste Stiftpositionen wurden durch Linien verbunden
Die grauen Flächen in Bild 69 stellen die schwarzen Punkte aus den Differenzbildern dar und die Kreuze sind die Mittelpunkte dieser grauen Flächen. Die beiden Linienzüge können nicht zusammenstossen, da die Mittelpunkte zweier zusammenstossender Flächen mit einer Breite von je fünf Pixel einen Abstand von fünf Pixel haben.
5.3.3 Wort 3: All
Das Wort "All" (8) wurde von Thomas von Siebenthal geschrieben und entstammt dem letzten Satz von Bild 63.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Bild 70: Jedes neunte Einzelbild der Bildsequenz des Wortes "All"
Folgende Parameter wurden bei der Erfassung der Stiftpositionen verwendet:
| Parameter | Wert | |||
| Masksize | 2 | |||
| Winsize | 40 | |||
| Area | 0.1 | |||
| Lookahead | 3 | |||
| Otsuvariance | 40 | |||
| Method | Neighbour | |||
| Intermin, Intermax, Intergap | 5, 10, 3 | |||
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Bild 71: Ablauf der Erfassung des Wortes "All"
Am Wort "All" fällt nur folgendes auf: Es gibt einige verstreute Punkte, in Bild 71 erkennbar als isolierte Kreuze, die das Resultat aber nicht beeinflussen, da die Interpolationsroutine isolierte Punkte ignoriert. Solche Punkte haben in der Liste der erfassten Stiftpositionen keine Nachbarn oder nur zu weit entfernte. Daher werden diese Punkte nicht mit anderen Punkten verbunden und haben so keinen negativen Einfluss auf das Resultat.
5.3.4 Wort 4: but
Das Wort "but" (9) wurde von Thomas von Siebenthal geschrieben und entstammt dem vierten Satz von Bild 63.
|
|
|
|
|
|
|
|
|
|
|
|
Bild 72: Jedes achte Einzelbild der Bildsequenz des Wortes "but"
Folgende Parameter wurden bei der Erfassung der Stiftpositionen verwendet:
| Parameter | Wert |
| Masksize | 2 |
| Winsize | 40 |
| Area | 0.1 |
| Lookahead | 3 |
| Otsuvariance | 40 |
| Method | Neighbour |
| Intermin, Intermax, Intergap | 5, 10, 5 |
|
|
|
|
|
|
|
|
|
Bild 73: Ablauf der Erfassung des Wortes "but"
Bei diesem Wort wurde das "b" gut erfasst; sogar die Anbindung des Bauches an den senkrechten Strich ist erfasst worden. Einzig problematisch ist der kleine horizontale Strich beim "t". Dieser ist leider in zwei Teile, links und rechts vom senkrechten Strich, zerfallen, da die doppelte Auftragung von Tinte auf das Papier bei einer Kreuzung auf dem Blatt keine Veränderung bewirkt hat. Weil zwischen den beiden Teilstücken der horizontalen Linie ein zu grosser Abstand ist, konnte die Interpolationsroutine auch keine Verbindung erzeugen.
Nachdem hier nun vier Beispiele für eine gute Erfassung der Stiftpositionen aufgezeigt wurden, finden sich im nächsten Abschnitt Worte, welche Probleme bei der Verarbeitung aufweisen. Alle Resultate der Eingabesequenzen aus Anhang C werden in Anhang D abgedruckt. Leider kann dort aus Platzgründen nur das Offline Bild abgebildet werden, welches aus den erfassten Online-Daten konvertiert wurde.
5.4 Probleme beim Erfassen
Beim Verarbeiten der Eingabesequenzen traten vier Kategorien von Problemen zu Tage:
Die vier Probleme werden in den nächsten Abschnitten näher erläutert und anhand von Beispielen illustriert. Mögliche Lösungsansätze zur Verhinderung der Probleme werden im Kapitel 6 aufgezeigt.
5.4.1 Bewegtes Papier verschiebt die Buchstaben
Weil das Papier nicht absolut fest mit dem Tisch verbunden war konnte die Hand des Schreibers das Blatt Papier auf und ab bewegen. Dies erfolgte v.a. dann, wenn der Schreiber seine Hand anhob um diese nach rechts zum nächsten Buchstaben zu schieben. Dies hat zur Folge, dass die Positionen des Schriftzuges sich wie in Bild 74 verschieben, obwohl vorausgesetzt wird, dass der Schriftzug immer am gleichen Ort sein sollte.

Bild 74: Durch die Bewegung des Papiers bewegen sich die Buchstaben des Schriftzuges um mehrere Pixel nach oben.
Durch die Verschiebung des Schriftzugs wird die Erstellung der Differenzbilder empfindlich gestört. Es kann vorkommen, dass ein bereits erkannter Linienzug um einige Pixel nach oben verschoben wird und dort zu dunklen Punkten im Differenzbild führt. Diese Punkte werden dort unbeabsichtigterweise auch zur Erkennung der Stiftposition benutzt und verunmöglichen korrekte Resultate.
5.4.2 Schwache horizontale Linien
Einige horizontalen Linien sind nur hellgrau anstatt schwarz ausgeprägt (vgl. Bild 75 und Bild 77). Hierdurch besteht an diesen Stellen nur noch ein minimaler Kontrast zwischen Hintergrund und Schriftzug. Die schwachen Linien sind im Differenzbild, v.a. wenn noch Korrekturen aus nachfolgenden Bildern eingeflossen sind, fast nicht mehr erkennbar und werden in der Binärisierung zu weissen Punkten und daher auch nicht als Stiftposition berücksichtigt.
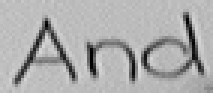
Bild 75: Die horizontalen Linien (mit Pfeilen markiert) aller Buchstaben des Wortes "And" sind nur schwach ausgeprägt.
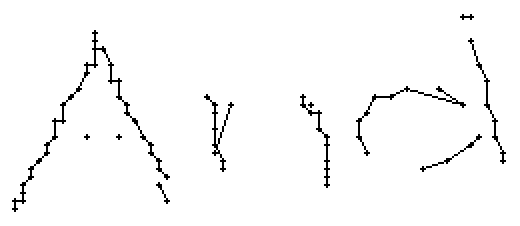
Bild 76: Die schwachen horizontalen Linien von Bild 75 führen zu drei mit einem Pfeil markierten Lücken in den Online-Daten
Beispiele von Worten mit solch schwachen Linien können in Bild 75 und Bild 77 betrachtet werden. Die schwachen horizontalen Linien führen in den Online-Daten von Bild 76 und Bild 78 zu markanten Lücken. Diese Lücken sind zu gross als dass sie interpoliert werden könnten.

Bild 77: Die horizontalen Linien (mit Pfeilen markiert) der Buchstaben "T" und "e" des Wortes "The" sind im Vergleich zum Hintergrund zu hell.
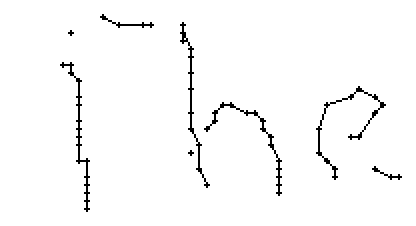
Bild 78: Die schwachen Linien von Bild 77 führen auch hier zu zwei Lücken
5.4.3 Doppelt geschriebene Linienzüge
Bei Buchstaben wie "h", "n" und "m" werden einzelne Linienstücke zweimal vom Stift mit Tinte überstrichen. Im ersten Beispiel von Bild 79 werden sowohl die erste als auch die zweite senkrechte Linien des Buchstaben "m" zweimal gezeichnet; nämlich zuerst einmal beim Strich nach unten und dann wieder beim Strich nach oben um dann einen Bogen nach rechts anzuschliessen. Bei der reinen Betrachtung der Differenzbilder ist dies nicht ersichtlich, da beim zweiten Zeichnen dieses Liniensegmentes keine Veränderungen mehr stattfinden.
|
|
|
|
|
|
|
|
|
|
|
|
Bild 79: Jedes fünfte Einzelbild der Bildsequenz des Wortes "I’m"
Der Buchstaben "m" besteht in den Online-Daten also nicht mehr aus einem Linienzug mit zwei "Torbogen", sondern aus drei Linienteilen: Einem senkrechten Strich und zwei nach rechts aneinander gehängten Halbbogen. Dies ist in der Darstellung der Online-Daten in Bild 80 gut ersichtlich.
|
|
|
|
|
|
|
|
|
|
|
|
Bild 80: Entstehung des Buchstaben "m" anhand der Online-Daten
Das gleiche Verhalten lässt sich auch beim Buchstaben "n" des Wortes "in" beobachten. Auch dort werden die Eingabedaten von Bild 81 nicht in einen einzigen Linienzug für den Buchstaben "n" konvertiert sondern ergeben, wie in Bild 82 ersichtlich, zwei getrennte Linienzüge: Ein senkrechter Strich mit einem rechts davon liegenden Halbbogen.
|
|
|
|
|
|
|
|
|
Bild 81: Jedes sechste Einzelbild der Bildsequenz des Wortes "in"
|
|
|
|
|
|
|
|
|
|
|
|
Bild 82: Entstehung des Wortes "in" anhand der Online-Daten
5.4.4 Geschwungene Aufstriche
Die letzte Problemgruppe betrifft geschwungene Buchstaben wie "e" und "l". Während dem Aufstrich des Buchstaben "l" (vgl. Teilbilder 3 und 4 in Bild 83) wird die frisch aufs Papier aufgetragene Tinte vollständig vom Stift verdeckt, denn dieser liegt genau auf der Linie "Tinte - Kamera". Im 5. Teilbild von Bild 83 wird dann auf einen Schlag das ganze senkrechte Linienstück vom Aufstrich beim "l" sichtbar und schlägt sich im Differenzbild als dunkle Punkte nieder. Die restlichen Teilbilder 6 bis 9 von Bild 83 verlaufen wieder wie erwartet.
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
Bild 83: Jedes vierte Einzelbild der Bildsequenz des Wortes "All"
Das Verdecken des Linienzuges und das anschliessende Wiedererscheinen des ganzen Linienzuges auf einen Schlag führt in den Online-Daten zu falschen Verbindungen. Der Aufstrich des Buchstabens "l" beginnt normal. Dann wird nur der oberste Teil des Bogens erkannt (Teilbild 4 von Bild 84), der Rest des Aufstriches fehlt noch. Dieser Teil wird am Ende des oberen Bogens nicht mehr vom Stift verdeckt und auf einmal sichtbar. Es kommt zu einer unerwarteten Verbindung vom oberen Teil des Bogens nach rechts (Teilbild 4 von Bild 84). Der Abwärtsstrich wird wieder erfasst. Die Problematik mit den sich kreuzenden Linien (Teilbilder 7 und 8 von Bild 84), auf die bereits in "5.3.2 Wort 2: brick" hingewiesen wurde, wird sichtbar. Das Ende des Bogens vom "l" ist durch den Aufstrich unterbrochen, da bei der Kreuzung keine neue Tinte mehr auf weisse Teile des Papiers aufgetragen wurde, sondern, für die Erstellung der Differenzbilder unsichtbar, eine bestehende Linie überschrieben wurde. Auch hier ist die Lücke zu breit, als dass sie interpoliert werden könnte.
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
Bild 84: Entstehung des Buchstaben "l" anhand der Online-Daten
Das gleiche Problem wie beim "l" von "All" wird auch in Bild 86 beim Buchstaben "e" des Wortes "the" illustriert. Im Teilbild 4 von Bild 85 verdeckt der Stift die soeben geschriebene Aufwärtslinie, um sie dann beim Übergang zu Teilbild 5 auf einmal erscheinen zu lassen.
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
Bild 85: Jedes fünfte Einzelbild der Bildsequenz des Wortes "the"
In den Online-Daten führt dies zu einem ungewollten Ausreissen des Linienzuges nach rechts (Teilbilder 6 und 7 von Bild 86). Ein Ausreisser, der nur wegen einer einzigen Stiftposition erzeugt wird (Teilbild 4 in Bild 86) könnte noch eliminiert werden, doch ein Ausreisser der wegen mehrerer falschen Stiftpositionen zu Tage tritt, kann nicht mehr korrigiert werden.
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
Bild 86: Entstehung des Buchstabens "e" anhand der Online-Daten
5.5 Test mit ETHZ-Handschrifterkenner
Alle bisherigen Resultate konnten nur visuell beurteilt werden. Hierbei musste der Benutzer subjektiv bewerten wie gut die Online-Daten der Entstehung des Schriftzugs entsprechen. Zwecks einer objektiveren Beurteilung und zur Feststellung, ob die mit diesem System gewonnen Online-Daten in der Praxis brauchbar sind, wurden Tests mit dem Handschrifterkenner der ETHZ durchgeführt. Diese Tests und deren Resultate werden hier vorgestellt.
Der Handschrifterkenner der ETHZ basiert auf "Time Delay Neural Networks" und "Hidden Markov Models" und ist gleichermassen für die Verarbeitung von Online- und Offline-Daten geeignet. Der Online-Teil dieses Handschrifterkenners wurde v.a. von Markus Schenkel (Dissertation [Sch95]) und von Isabelle Guyon entwickelt. Beim Offline-Teil waren Rolf Seiler und Markus Schenkel die treibenden Köpfe. Nähere Informationen zum ETHZ-Handschriftenerkenner können [Amm96, Seiten 83 – 89], [SGH95] und [SSE96] entnommen werden.
Für diese Tests wurde ausschliesslich der Online-Teil des Erkenners benutzt. Die Testdaten bestehen aus je 52 Wörtern für zwei Schreiber. Diese 104 Wörter wurden mit den visuell als optimal bestimmten Parametern erfasst und im Online-Format der ETHZ abgespeichert. Zum Nachtrainieren des Erkenners wurden Abwandlungen der Testdaten verwendet. Zur Erzeugung dieser abgewandelten Trainingsdaten wurden die drei Interpolationsparameter (vgl. "5.2 Parameter der Erfassungsroutine") in der unmittelbaren Umgebung der optimalen Werte variiert, kombiniert und damit die Online-Daten erstellt. Diese Trainingsdaten sind, aufgrund der minimal unterschiedlichen Parameter, sehr ähnlich zu den Testdaten. Generierte Trainingsdaten, welche mit den optimalen Testdaten übereinstimmen, werden nicht zum Trainieren verwendet. Hiermit wird die Forderung erfüllt, dass die Menge der Testdaten disjunkt zur Menge der Trainingsdaten sein soll.
Wenn die optimale Kombination der Interpolationsparameter (intermin, intermax und intergap) für ein Wort z.B. (5,8,3) ist, dann werden für jedes Tripel
die entsprechenden Online-Daten des aktuellen Worts erstellt. Sollte eine Variante dieser Online-Daten mit den Online-Daten der optimalen Kombination (5,8,3) übereinstimmen, wird sie nicht zum Nachtrainieren verwendet. Auf diese Weise entstehen pro Wort maximal 33-1 = 26 verschiedene Trainingsvariationen. Bei den in Anhang C und D vorgestellten Testdaten wurden für die 104 Test-Worte 2177 Trainingssets erstellt und zum Nachtrainieren verwendet.
Beim Nachtrainieren des ETHZ-Erkenners wurde auf einer bestehenden Datenbank (10) der ETHZ für Handschrift basiert. Die Tests wurden ohne Nachtraining, nach einem zehnfachen Nachtraining mit einem Lernfaktor von 0.2 des neuronalen Netzes, einem anschliessenden zehnfachen Nachtraining mit einem Lernfaktor von 0.1 und einem abschliessenden zehnfachen Nachtraining mit einem Lernfaktor von 0.05 durchgeführt. Bei den vier nachfolgenden Tests wurden drei verschiedene Wörterbücher verwendet: Kein Wörterbuch, das UNIX Wörterbuch mit 25144 englischen Worten und eine minimales Wörterbuch mit den 46 trainierten Wörtern.
Folgende Worterkennungsraten wurden erzielt:
Kein |
UNIX |
Minimales Wörterbuch |
|
Ohne Nachtraining |
|
|
|
| 10-faches Nach-training mit Lernfaktor 0.2 |
|
|
|
| 10-faches Nach-training mit Lernfaktor 0.1 |
|
|
|
| 10-faches Nach-training mit Lernfaktor 0.05 |
|
|
|
Interessant an diesen Resultaten ist, dass schon nach einem kurzen Training von ca. 3 Stunden die Erkennungsrate stark zugenommen hat. So konnte die Erkennungsrate mit dem UNIX Wörterbuch von 11.5% auf 53.8% gesteigert werden. Weitere Trainings mit einer kleineren Lernrate des neuronalen Netzes brachten nur noch minimale Veränderungen der Erkennugsrate. Die Resultate mit dem grossen UNIX Wörterbuch und dem minimalen Wörterbuch geben Rückschlüsse auf die untere und obere Schranke der Worterkennungsrate.
Ein Test mit einer grösseren Trainingsmenge (6667 Worte) brachte nur eine geringe Veränderung der Worterkennungsrate. Der dreimal so grosse Trainingsaufwand hat sich, angesichts der geringen Verbesserungen nicht gelohnt:
Kein |
UNIX |
Minimales Wörterbuch |
|
Ohne Nachtraining |
|
|
|
| 10-faches Nach-training mit Lernfaktor 0.2 |
|
|
|
| 10-faches Nach-training mit Lernfaktor 0.1 |
|
|
|
| 10-faches Nach-training mit Lernfaktor 0.05 |
|
|
|
Die Installation und Verwendung des ETHZ-Erkenners am IAM ist im Anhang E beschrieben. Dort werden auch die notwendigen Routinen zur Erstellung von Test- und Trainingsdatenbanken und zu deren Verarbeitung mit dem ETHZ-Handschrifterkenner vorgestellt.
1) Der detaillierte Aufbau dieser Datei kann dem Anhang B entnommen werden.
2) HTMLreport.pl ist ein PERL-Skript welches die Konfigurationsdatei einliest und dann von mpeg2points berechnen lässt. Es ist auch in der Lage, mehrere Parametervarianten zu verarbeiten, also z.B. eine Fenstergrösse von 40, 45 und 50 Pixel. Weitere Details können Anhang B entnommen werden.
3) mpeg2points berechnet genau eine Bildsequenz mit einer Konstellation von Parametereinstellungen. Dieses Programm kann sowohl direkt vom Benutzer aufgerufen werden oder wird, was anwenderfreundlicher ist, von HTMLreport.pl aufgerufen. Weitere Details findet der Leser im Anhang B.
4) viewimages erlaubt es dem Benutzer die Bounding-Box und das Intervall einer Eingabesequenz für ein spezielles Wort zu definieren. Alle anderen Parameter können hier, um einen ersten Startwert für Optimierungen zu erhalten, eingegeben werden. Als Resultat wird dann eine Konfigurationsdatei für die Applikation HTMLreport.pl erstellt. Weitere Details sind in Anhang B ersichtlich.
5) Das Programm viewpoints stellt die erfassten Stiftpositionen des Programmes mpeg2points grafisch dar. Hierbei können die Interpolationsparameter getestet werden und auch das Online-Format der ETHZ exportiert werden. Die genaue Beschreibung befindet sich in Anhang B.
6) In den Anhängen C und D wird dieses Wort WC_AN genannt.
7) In den Anhängen C und D wird dieses Wort WC_BRICK genannt.
8) In den Anhängen C und D wird dieses Wort WT_ALL genannt.
9) In den Anhängen C und D wird dieses Wort WT_BUT genannt.
10) Datei mixed-on-70-2211L.net mit der Netzarchitektur varmult9-70-2011L des ETHZ-Handschrifterkenners