
Kapitel 1 - Einleitung
In diesem Kapitel wird die vorliegende Arbeit in das Fachgebiet der Künstlichen Intelligenz und Mustererkennung eingeordnet und die zwei grundsätzlichen Ansätze der Handschrifterkennung eingeführt. Weiter werden die Ziele dieser Diplomarbeit aufgezeigt und die Arbeit gegliedert. Nach einer kurzen Erläuterung der verwendeten Hilfsmittel werden abschliessend andere Arbeiten vorgestellt, welche sich mit gleichen oder ähnlichen Fragestellungen befassen.
Die Handschrifterkennung wird in zwei grundsätzliche Methoden unterteilt (1): Einerseits in die Online-Erkennung und andererseits in die Offline-Erkennung, welche im Folgenden vorgestellt werden.
Bei der Offline-Erkennung (vgl. Bild 1) wird der Text mit einem Stift auf ein Blatt Papier geschrieben. Dieses Blatt Papier wird dann mit einem Scanner in den Computer eingelesen und liegt dort als Bild in Form eines binären, grauwertigen oder dreifarbigen zweidimensionalen Feldes vor. Die Informationen werden in einzelne Worte segmentiert und von einem Offline-Erkenner verarbeitet. Der Handschrifterkenner kann also nur statische Informationen des Texts als Ganzes verwenden; über die Entstehung des Texts liegen keine Informationen vor. Dafür ist die Erfassung der Daten sehr einfach – ein Blatt Papier kann fast überall problemlos beschrieben werden. Technische Hilfsmittel müssen erst beim späteren Schritt, der Erkennung des Texts, vorhanden sein.
Bild 1: Funktionsweise der Offline-Handschrifterkennung
Die Online-Erkennung (vgl. Bild 2) nutzt im Gegensatz zur Offline-Erkennung auch die zeitliche Information. Hierzu müssen aber bereits bei der Erfassung des Texts spezielle technische Hilfsmittel eingesetzt werden. Im Normalfall wird hierzu ein Grafiktablett verwendet, auf welchem der Benutzer das Blatt Papier mit einem speziellen Stift beschreibt. Der Stift ist mit dem Grafiktablett verbunden, welches kontinuierlich die Stiftposition an den angeschlossenen Computer übermittelt. Diese Stiftpositionen können dann auf dem Computer gespeichert werden und sofort oder später zur Erkennung des Texts verwendet werden. Der Erkenner arbeitet nicht mehr auf einem zweidimensionalen Feld, sondern einer Liste mit Tripeln. Die Zahlentripel enthalten die x- und y-Koordinaten des Stifts und den Zeitpunkt dieser Position. Die Informationen die dem Online-Erkenner zur Verfügung stehen sind eine Obermenge der Informationen die der Offline-Erkenner benutzt. Aus Online-Daten lassen sich problemlos Offline-Daten generieren.
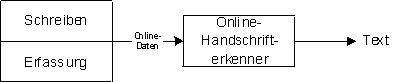
Bild 2: Funktionsweise der Online-Handschrifterkennung
Die Verwendung der Online-Handschrifterkennung verspricht bessere Resultate, da mehr Eingabedaten vorliegen. Die Offline-Handschrifterkennung ist jedoch weiter verbreitet. Dies liegt v.a. an der viel einfacheren Erfassung der Handschrift. Zudem kann die Offline-Erkennung der Handschrift lange Zeit nach dem Schreiben des Texts geschehen. So wird diese Erkennungsmethode beispielsweise zum automatischen Erkennen von Postleitzahlen auf Briefpost oder zur Verarbeitung von Checkformularen verwendet. Die Online-Erkennung ist aufgrund der Notwendigkeit technischer Hilfsmittel bei der Datenerfassung weniger verbreitet. Am ehesten trifft man Online-Handschrifterkennung in kleinen Notizbuch-Computern (2) an. Hier kann mit einem Stift direkt auf einem drucksensitiven Bildschirm geschrieben und gezeichnet werden.
1.2 Motivation und Ziele dieser Arbeit
Der grosse Vorteil der Offline-Handschrifterkennung besteht darin, dass die Eingabe der Daten sehr einfach ist. Man lässt den Benutzer ein Blatt Papier beschreiben und liest dieses anschliessend mit einem Scanner in den Computer ein. Hierbei wird der Benutzer nicht mit den technischen Hilfsmitteln konfrontiert und kann in seiner gewohnten Umgebung schreiben. Also mit seinem bevorzugten Stift auf einem Blatt Papier auf seinem eigenen Schreibtisch.
Bei der Online-Handschrifterkennung muss bekannt sein, wie der Schriftzug zeitlich entstanden ist. Das hierzu geeignete Grafiktablett stellt für den Benutzer ein Hindernis oder sogar eine Hürde dar und entspricht nicht dem gewohnten Umfeld.

Bild 3: Funktionsweise der Online-Handschrifterkennung mit dem hier vorgestellten System (grau hinterlegt) zur Erfassung von Online-Daten mit einer Videokamera
Diese Arbeit zeigt einen neuen Weg zur Erfassung von Daten für Online-Handschrifterkennung auf (vgl. Bild 3). Der Benutzer wird beim Schreiben in seiner gewohnten Umgebung gefilmt. Aus der gewonnenen Bildsequenz werden Online-Daten für einen Online-Handschrifterkenner extrahiert. Als einziger Unterschied zum konventionellen Schreiben wird der Benutzer von einer Videokamera gefilmt. Mit Hilfe modernster Technik kann diese Kamera aber so klein und unauffällig sein, dass sie vom Benutzer gar nicht wahrgenommen wird.
Bei der vorliegenden Arbeit handelt es sich um einen Prototyp des oben beschriebenen Idealbilds eines neuen Eingabemediums. Folgende Einschränkungen müssen bei der Benutzung des Systems beachtet werden:
Mit obengenannten Einschränkungen ist das System sicherlich noch nicht komfortabler als ein Grafiktablett, doch es wird eine mögliche Richtung einer späteren Weiterentwicklung und eines zukünftigen Eingabesystems zur Online-Handschrifterkennung aufgezeigt. Der Prototyp könnte leicht erweitert werden, so dass die Einschränkungen gelockert werden könnten.
Diese Arbeit ist Top-Down gegliedert. Von Kapitel zu Kapitel werden die groben Züge der Arbeit immer weiter verfeinert und detaillierter vorgestellt. Das erste Kapitel soll einen kurzen Überblick über die Handschrifterkennung geben und die vorliegende Arbeit in das Fachgebiet der Mustererkennung einordnen.
Im zweiten Kapitel – Systemüberblick – wird ein grober Überblick über das ganze System gegeben. Hierbei wird der Datenfluss durch die einzelnen Komponenten vorgestellt.
Das dritte Kapitel – Systemkomponenten – vertieft die Arbeitsweise der im vorangehenden Kapitel definierten Komponenten. Die Arbeitsweise der Komponenten wird unabhängig von der Implementation erläutert und das Schwergewicht wird auf die fachlichen und wissenschaftlichen Aspekte der Mustererkennung gelegt.
Im vierten Kapitel – Implementation – wird auf das objektorientierte Design des Systems und die Implementation in C++ eingegangen. Auf Code wird verzichtet, wo nötig werden wichtige Algorithmen durch Pseudocode beschrieben.
Das fünfte Kapitel – Resultate – widmet sich der Besprechung der Resultate dieser Arbeit. Die Testdaten und die zugehörigen Resultate werden vorgestellt. Die sich daraus ergebenden Probleme werden aufgezeigt und besprochen. Weiter werden die Resultate und Erfahrungen der Tests der Online-Daten mit dem Handschrifterkenner der ETHZ kommentiert.
Im sechsten und letzten Kapitel – Zusammenfassung und Ausblick – werden die Resultate und Möglichkeiten dieser Arbeit zusammengefasst, Lösungsansätze für die Probleme aus dem fünften Kapitel aufgezeigt und Verbesserungen und Erweiterungen für die Zukunft umrissen.
In den Anhängen werden spezielle Themen konkreter und ausführlicher dokumentiert. So sind dort alle Testdaten abgedruckt, wird die Benutzung der einzelnen Programme erklärt und auf die Anwendung des Online-Erkenners der ETHZ eingegangen.
Zur Bearbeitung dieser Diplomarbeit wurden viele Informatik-Hilfsmittel verwendet. Zur Erfassung der Videobilder wurde eine Videokamera von Siemens verwendet. Die Videodaten wurden auf einer SUN Workstation mit der SunVideo-Card (4) erfasst und als MPEG-Datei (5) abgespeichert. Die resultierenden Videodateien wurden mit umgewandelt.mpeg2decode (6) und ppm2pgm (7) in einzelne Graustufenbilder
Zur Implementation des Codes wurden die Programmiersprachen C++ (8) und PERL (9) verwendet. Die Darstellung wird mittels X11 (10) und Motif (11) vorgenommen. Hierbei lässt sich der Quellcode mit dem GNU (12) C++-Compiler sowohl unter Solaris 2.x als auch unter Linux übersetzen. Die Aufbereitung der Bilder für X11 geschieht mit Routinen aus dem bekannten Grafikprogramm xv.
Allgemeine Informationen über die digitale Bildverarbeitung lieferten die Vorlesung Digitale Bilder [Bie96] und die Bücher [KIZ92], [Hab89] und [BaB82].
Der Dokumentation der vorliegenden Arbeit wurde mit Microsoft Word 97 geschrieben. Eine unerlässliche Hilfe war dabei das Buch [NiA97] welches konkret auf Probleme bei der Erstellung grösserer wissenschaftlicher Arbeiten mit Word eingeht. Die Grafiken wurden mit Corel DRAW 8.0 und Visio 4.0 erstellt. Die Bilder wurden mit xv, Corel PhotoPaint 8.0 und Paint Shop Pro 4.0 verarbeitet.
1.5 Andere Arbeiten auf diesem Gebiet
Es existieren wenige Arbeiten auf dem Gebiet der alternativen Erfassung von Online-Daten. Dem interessierten Leser können aber die drei nachfolgenden Arbeiten Ideen und Ansätze zur aufzeigen:
Toshinori Yamasaki, Katsuyoshi Manabe [MYa95] und Tetsuo Hattori [YMH95]: Diese zwei Versionen des Artikels sind in japanischer Sprache abgefasst. Das englische Abstract und die Illustrationen vermitteln die Idee ausreichend. Zur Bestimmung der Stiftposition wird das Zeichnen eines japanischen Schriftzeichens mit einer Videokamera erfasst. Dieses Schriftzeichen ist 5 auf 5 cm gross und wird mit einer Auflösung von 256 * 256 Pixel in 64 Graustufen abgetastet. Die Position des Stifts wird aufgrund der Differenz zwischen benachbarten Einzelbildern der Bildsequenzen bestimmt. Störende Artefakte wie Hand, Schreibstift und Schatten müssen eliminiert werden. Die drei Autoren weisen auf die Benutzerfreundlichkeit dieses neuen Eingabemediums hin. Der Benutzer muss sich nicht an ein Grafiktablett gewöhnen, sondern er kann mit dem gewohnten Stift auf einem Blatt Papier schreiben.
Mario E. Munich, Pietro Perona [MPe96]: Munich und Perona bestimmen die Position des Stifts, indem sie dessen Spitze in den Einzelbildern verfolgen. Mit einem sog. Kalman-Filter beschränken sie den Suchraum um die Geschwindigkeit des Systems zu verbessern. Aus dieser Erkennung resultiert der zurückgelegte Weg der Stiftspitze, wobei noch nicht unterschieden wird, ob auf dem Blatt geschrieben wurde oder nicht. Zur Bestimmung, ob der Stift auf dem Papier aufgesetzt ist oder nicht, wird die Trajektorie in Segmente unterteilt und basierend für jedes Segment einzeln eine Entscheidung getroffen. Hierzu werden die Segmente mit der Tinte auf dem Papier verglichen und entweder eine Beziehung hergestellt (Stift abgesetzt resp. pen down) oder nicht (Stift in der Luft resp. pen up). Ihr Schwergewicht liegt in der Integration dieses Eingabemediums in den XEROX Digital Desk und der Verarbeitung der Daten in Echtzeit.
Roger Ammann [Amm96]: Roger Ammann beschreibt in seiner Diplomarbeit eine ganz andere Variante der Gewinnung von Online-Daten. Er konvertiert Offline-Daten, also statische Bilder der geschrieben Worte in Linienzüge, indem er diverse Kriterien für Handschrift hinzuzieht. Seine Resultate testete er mit dem Online-Handschrifterkenner (vgl. [Sch95] und [SSE95]) der ETHZ. Hierbei erzielte er auf dem nachtrainierten Online-System eine Erkennungsrate von 97.4 %.
1) Eine umfassendere Einführung in die Handschrifterkennung geben [Amm96] und [Rot93].
2) Auch PDA (Personal Digital Assistant) genannt. Bekannte Beispiele hierzu sind das Newton Messagepad von Apple und der PalmPilot von 3Com. Der Newton wird auf den Benutzer trainiert und erkennt freie, kursive Handschrift. Beim PalmPilot muss sich der Benutzer eine handschriftähnliche Schrift (Graffiti) aneignen.
3) Das 4 auf 1.5 cm grosse Wort "Please" wurde vom den beiden Schreiber in 13 resp. 15 Sekunden geschrieben.
4) Weitere Informationen können dem entsprechenden User’s Manual [Sun94] entnommen werden.
5) "MPEG ist das Akronym der Moving Pictures Export Group die, basierend auf den Ergebnissen von JPEG, seit 1988 Verfahren zur Kompression von bewegten Bildern entwickelt hat. Zielsetzung war unter anderem die industrielle Nutzung des Verfahrens, sowohl für CD-ROM-Videodaten als auch für Digitales Fernsehen. Das MPEG-Verfahren komprimiert zunächst ein Standbild und ermittelt für eine Reihe folgender Einzelbilder jeweils Differenzbilder (genauer: Bewegungsvektoren), die ebenfalls komprimiert werden.". Zitat aus [iX398].
6) mpeg2decode ist ein Programm der MPEG Software Simulation Group (MPEG-L@netcom.com), welches MPEG-1 und MPEG-2 Videodateien in verschieden Bildformaten wie TGA, X11 oder PPM konvertieren kann. Die erzeugte Sequenz von Einzelbildern kann dabei aufsteigend numeriert werden.
7) Das UNIX Kommandozeilen-Programm ppmtopgm wandelt TrueColor-PPM-Bilder in Graustufenbilder um. Hierbei werden die 3 Farbkomponenten folgendermassen zu einem Grauwert quantisiert:0.299 * Rot +0.587 * Grün + 0.114 * Blau. Die dazugehörige Programmbibliothek PBMPLUS (Extended Portable Bitmap Toolkit, 1991) stammt von Jef Poskanzer (jef@well.sf.ca.us).
8) Als einfache Einführung in C++ kann [Ere95] dienen. [Sku94] handelt alle wichtigen Aspekte von C++ ab, ist aber oft nicht einfach zu verstehen. [Bre96] und [Cop92] sind für weitere Details der Sprache C++ hilfreich. Beim Aufbau eines grösseren Systems mit C++ verhelfen [Sco95] und [Sco96] zu einer guten Implementation.
9) PERL ist eine umfangreiche und mächtige Programmiersprache zur Verarbeitung von Texten. V.a. als erweiterte Scripting Language leistet PERL sehr gute Dienste. PERL wird in [WaS92] von den Entwicklern vorgestellt. [Vro96] ist ein hilfreiches Nachschlagewerk für die neueste Version 5 von PERL.
10) X11 ist das Fenstersystem unter Unix. Es übernimmt die netzweit transparente Behandlung von Fenstern, bildern und Aktionen. Die Darstellung der grafischen Benutzeroberfläche wird von Toolkits wie Motif übernommen. X11 wird dem Leser in [JoR95] und [CGR92] näher gebracht.
11) Motif ist ein Toolkit für X11. Motif übernimmt die Darstellung der Fensterelemente innerhalb von X11 und bietet viele Hilfsroutinen zur einfacheren Handhabung von X11. [Kim95] kann gleichermassen als Referenz und zum Erlernen von Motif empfohlen werden.
12) GNU ist ein Projekt zur Erstellung eines freien UNIX-Systems. Die GNU-Tools begleiten die meisten UNIX-Entwickler. Die Verwendung der verschiedenen GNU-Entwicklungs-Tools wird in [LOr97] beschrieben.